

Deep Engineering #41: Scaling C++ the Right Way with Sam Morley
Template metaprogramming, cache-aware design, concurrency models, and why learning Rust might actually make you a better C++ programmer



C++ Memory Management Masterclass (Live) — Back for the 3rd Run

Learn ownership, RAII, smart pointers & allocators to eliminate leaks/UB—live hands-on with Patrice Roy—#1 bestselling author of C++ Memory Management and ISO C++ Standards Committee (WG21) member. Online: Sat Apr 11, 10:30 AM–Sun Apr 12, 4:00 PM ET. Limited seats.
✍️ From the editor’s desk,
Welcome to the 41st issue of Deep Engineering!
As AI scaling hits the memory wall, system performance is increasingly limited by data movement rather than raw compute power. This shifts the optimization focus toward data locality because adding cores provides no benefit when bandwidth bottlenecks the system. Writing fast code now requires precise control over memory layout and concurrency, yet these techniques often introduce complexity that becomes unmanageable as codebases grow.
That specific tension defines this week’s feature with Sam Morley, Research Software Engineer and Mathematician at the University of Oxford and author of The C++ Programmer’s Mindset.
Building on our earlier discussion in Part 1 around decomposition and abstraction costs, today's issue digs deeper into the guiding principles for scaling C++ systems. It covers how teams can keep complexity under control as codebases grow, why template metaprogramming deserves extreme caution, and why thinking with the machine is non-negotiable when optimising cache layout.
Let’s get started.
Stop Building Vault

Secrets, PKI, & PAM in one platform. Postgres-backed. No custom orchestration. Flexible deployment.
Adopting the C++ Programmer’s Mindset (Part 2) with Sam Morley
Before listing any specific practices, Morley introduces a concept he returns to repeatedly. He calls it the future you.
“Future you is your future self and for all intents and purposes this is a different person,” Morley says. “When you’re writing some code, you understand things the way they are in the context of what you’re doing at the moment. Future you will have lost this context. So, when you come back to your code in a month, six months, a year’s time and you look at it and you think what was I thinking — almost surely the answer to that is: I don’t know.”
The practical implication is easy to skip under deadline pressure, but it could be costly to ignore. Comments are not just for teammates. They are messages to yourself, written at the moment of maximum understanding, for a future reader who no longer has that understanding. Morley is explicit that this does not mean narrating the obvious. What he does instead, particularly on mathematically intricate work, is write large block comments that describe where the process is, how the next section works, and what the algorithm is intended to achieve. “These comments save me so much pain when I jump off the project for a week and then go back and have to remember exactly what I was trying to do.”
Beyond comments, Morley points to three C++ specific practices that matter most for scalability. The first is a strict separation of concerns. Numerical computation should not live in the same place as user-facing code. Components should be modular enough to be tested in isolation. This also pays dividends when distributing computation across clusters, because reusable tight-loop routines can be dropped into different distribution mechanisms without rework.
The second practice is thinking about thread safety earlier than you think you need to. Designing class members with that future in mind costs almost nothing early and can be enormously expensive to retrofit later. The third is keeping your build system clean. Morley uses CMake and is emphatic about this. “Having a broken build system is far worse than having broken code. It’s much harder to figure out what exactly has gone wrong if your build system is broken.” Build systems accumulate debt quietly and the consequences arrive at the worst possible moment, usually when you need to extract a component into its own library under time pressure.
When metaprogramming becomes the problem
“I’ve seen some horrendous template metaprogramming in my life,” Morley reflects. “I’ve written some horrendous template metaprogramming in my life. I’m going to be the first one to admit that it’s never worth it.”
The target here is the elaborate kind: deeply nested type machinery and SFINAE-heavy enable_if chains. Instantiating a complex template metaprogram can easily double compile time for a single translation unit. At scale, across thousands of files, the cost becomes structural. Morley notes this is exactly why Google kept metaprogramming to an absolute minimum when writing Abseil. Modern C++ has reduced the genuine need for TMP significantly. Concepts and constexpr functions cover much of what engineers used to reach for TMP to solve, with readable syntax and without the compile time penalty.
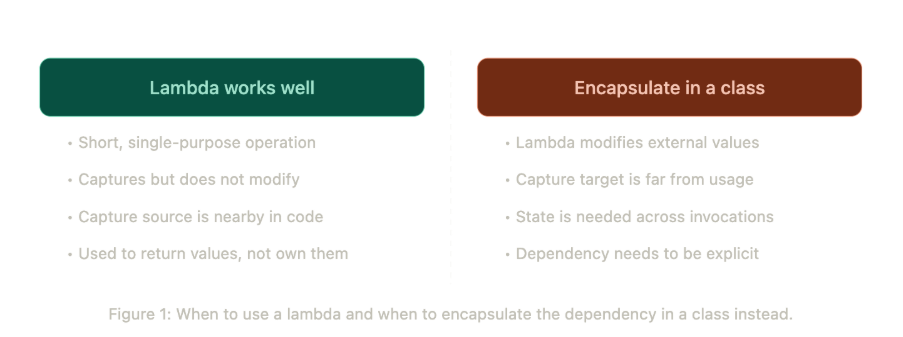
Lambdas are a different conversation. Used correctly, Morley thinks they are one of the most readability-enhancing tools in the language. Used carelessly, they introduce exactly the kind of invisible coupling that makes the future you miserable. His specific warning is about lambdas that capture and modify values defined far away from where the lambda is used. “Every time you think what is this lambda doing, it’s modifying something that you’ve not looked at for a long time because your screen has been further down the page.” In cases where a lambda is the only place that reads or writes a particular value, Morley argues the value almost certainly belongs inside a class, where the ownership and mutation path are explicit.
Thinking with the machine
Morley uses a road analogy to introduce hardware-aware programming. If you are driving down an unfamiliar road in the dark, you slow down because you cannot see what is ahead. Knowing the road means you can go faster without risk. The system you are running the code on is the road, the code you are writing is the car, and understanding the road conditions means you can drive faster with confidence.
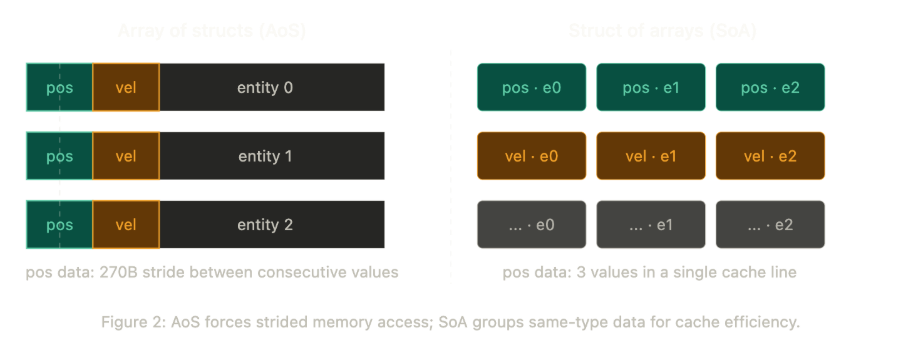
The most practically important piece of hardware to understand is the cache hierarchy. Cache behavior is invisible in the code but determines a large part of actual runtime performance. The canonical example comes from the games industry: the debate between Array of Structs (AoS) and Struct of Arrays (SoA).
If you represent each game entity as a large struct and store those structs in a vector, then iterating over position data means striding across the full width of each struct to reach the next position value. “Big strides are bad for the cache. What you really want is all of the position data to be close together.”
The alternative is to separate data by type, storing all position values together and all velocity values together, so that each field is laid out contiguously in memory rather than interleaved across structs. As Morley puts it: “This transformation basically doubles or quadruples your throughput because now you don’t have to step over all of the useless data in order to update your position.”
Matrix multiplication illustrates the same principle at a more concrete level. In one direction, data access is sequential and cache-friendly. In the other direction, moving between rows in a column means jumping across memory in steps as wide as the entire matrix, which is exactly what the cache is designed to avoid. The standard mitigation is tiling: load a small tile of the matrix, do as much computation as possible on that tile, then move to the next one. Morley walks through a tiled implementation in the book and notes roughly a four-times improvement over the naive approach from tiling alone, before any SIMD or pipelining optimisations are applied.
Branch prediction and SIMD matter too, but Morley is careful about context. For general-purpose application code, the compiler will usually make reasonable decisions, and the latency bottleneck is more often a network call or a disk write than an instruction pipeline stall. These details start to matter seriously when throughput is the primary constraint: training large models, running physics simulations, anything where a microsecond saved per operation compounds into meaningful wall-clock time across billions of invocations. “Taking an extra microsecond to do a calculation is devastating when you have to do that a billion times.”
Concurrency: two models, two risk profiles
Morley distinguishes two fundamentally different multi-threaded scenarios that require different mental models.
The first is data parallelism. A large dataset split across threads, each thread operating on its own independent range with no shared state. “There’s never any overlap. Each thread goes away, does its work, and the results are put in the buffer.” This is relatively safe territory. Parallel algorithms and OpenMP handle much of the machinery, and as long as the data partition is clean and there is no self-referential access, data races are structurally prevented.
The second scenario is harder. Multiple worker threads operating on shared state within a larger system. A dispatch queue is the typical pattern, where a main thread stacks work items and worker threads pull from the queue. Here, ownership discipline becomes non-negotiable.
Morley’s design goal is simple to state and difficult to achieve: only one thread, one function, one whatever should be able to modify a value at any given time. There are two ways to achieve this. The first is architectural: design the program so that each thread exclusively owns its data and never touches another thread’s values. The second is synchronisation: use atomics, mutex-locked values, or other thread-safe mechanisms to control access.
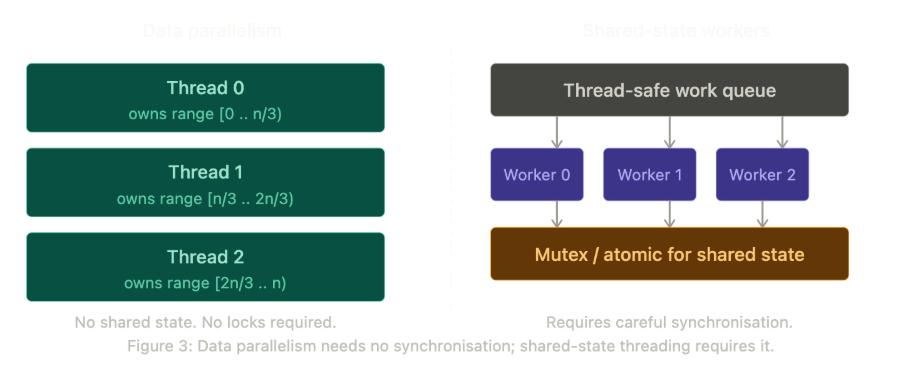
Morley urges engineers to read the synchronisation documentation carefully before reaching for any of these tools. Deadlocks happen when engineers use them without fully understanding their semantics. The architectural solution is always preferable when achievable: if you can design the program so that each thread never touches another thread’s data, you eliminate the entire class of problem. When you cannot, synchronisation primitives are available, but the burden of correctness falls entirely on the engineer.
Memory safety and the Rust argument
The issue closes on a topic that provokes strong reactions in C++ communities. With around 70% of serious security vulnerabilities attributed to memory safety failures in C and C++ code, the question of whether the language itself is the problem is not academic.
Morley’s answer is direct. “Go and learn some Rust.”
He anticipates the objection. “A lot of C++ programmers turn their nose up when Rust is mentioned. Generally, the feeling is: we don’t need Rust, we can do all of this in C++. But that’s not the point.” The point is that the Rust compiler forces a specific kind of thinking about ownership and lifetime that C++ leaves entirely to the developer. Rust’s sync and send traits enforce thread safety at the type system level. Unsafe code is marked explicitly, which means the developer makes a deliberate choice to step outside safe boundaries rather than doing so accidentally. “Learning a bit of Rust will make you better at writing safe C++. The reverse is not true.”
For engineers who are not yet ready to invest in Rust, Morley's immediate C++ recommendations are practical and specific. Prefer std::array over C-style arrays. Use smart pointers instead of manual memory management; writing operator new directly in application code is an antipattern at this point. Use std::span rather than raw pointers when passing data around. Avoid the C standard library IO functions entirely: gets, puts, sprintf, and their relatives have documented vulnerabilities and safer equivalents exist.
“The best-case scenario for a bad memory access is a crash. If it goes unnoticed, it could happen for months before you notice that this has been producing garbage the entire time. By which point you’ve wasted months.”
The throughline from Part 1 holds here. Whether the subject is decomposition, abstraction, maintainability, or memory safety, Morley keeps returning to the same discipline: be conscious of what you are doing, understand the costs of your choices, write for the person who will read the code next, and treat the machine as a collaborator rather than a black box.
🔍 In case you missed it…
The complete Chapter 1 from Sam Morley’s book, The C++ Programmer’s Mindset 👇



🛠️ Tool of the Week
Google Benchmark — A microbenchmark support library for C++
Google Benchmark is an open-source framework for measuring the performance of isolated C++ code so you can test cache-aware designs and tight-loop optimizations with high precision.
📎 Tech Briefs
C++26 Finalizes Technical Work — The ISO committee completed the C++26 draft in London, locking in features like compile-time reflection, memory safety improvements, and contracts ahead of final approval.
Rust 1.94.1 Shipped — A point release that fixes compiler regressions, resolves clippy false positives on match arms, and updates Cargo dependencies to address critical CVEs.
RustRover 2026.1 Released — JetBrains introduced cargo-nextest integration, a call hierarchy view, LLDB 21 upgrades, and improved DWARF indexing for procedural macros.
CppCon 2026 Opens Registration — Registration is open for the Colorado event, with sessions covering AI infrastructure, low-latency design, and hardware-aware performance.
Linux Kernel 7.0 Approaches — After Linux 6.19, the merge window for 7.0 is now open, pointing to a major version release expected later this April.
That’s all for today. Thank you for reading this issue of Deep Engineering.
We’ll be back next week with more expert-led content.
Stay awesome,
Saqib Jan
Editor-in-Chief, Deep Engineering
If your company is interested in reaching an audience of senior developers, software engineers, and technical decision-makers, you may want to advertise with us.
 | A guest post by
|