

Deep Engineering #37: Shreyans Doshi on building C++ trading systems under 50µs
Kernel bypass, memory pools, and the latency budget every performance engineer should know


C++ Memory Management Masterclass (Live) — Back for the 3rd Run

Back by demand (3rd run). Learn ownership, RAII, smart pointers & allocators to eliminate leaks/UB—live hands-on with Patrice Roy—#1 bestselling author of C++ Memory Management and ISO C++ Standards Committee (WG21) member. Online: Sat Apr 11, 10:30 AM–Sun Apr 12, 4:00 PM ET. Limited seats.
✍️ From the editor’s desk,
Hello, It’s a privilege to take over as the new Editor-in-Chief of Deep Engineering, which already has a strong foundation and readership.
With support from colleagues at Packt, I also plan to expand coverage into system design, cloud native applications, platform engineering, and other areas of modern software development where engineering leaders have strong interest.Thank you.
Welcome to the 37th issue of Deep Engineering!
This week’s Android Security Bulletin includes a familiar warning for anyone who builds systems close to the metal: “There are indications that CVE-2026-21385 may be under limited, targeted exploitation.” Whatever the specific exploit chain looks like, memory corruption remains a production-grade failure mode, not a theoretical one.
This week’s Expert Insight comes from Shreyans Doshi (ex Flow Traders, Morgan Stanley), a software engineer who has spent the last several years building trading infrastructure in C++ and Rust. His article, From NIC to P99: Engineering Low-Latency C++ Trading Systems in 2026, walks through the full stack of decisions required to hit a p95 wire-to-wire latency under 50 microseconds. It covers kernel bypass and memory pool design, NUMA affinity, hardware clock selection, and observability at nanosecond granularity.
This issue answers three questions that recur in performance-critical systems (trading and otherwise):
Where the latency budget actually goes once you include the NIC, kernel boundary, CPU topology, caches, and clocks—not just business logic.
What belongs on the critical path vs. off it, using a clean pipeline model (ingestion → checks → pricing → strategy → OMS).
How to measure regressions early, using stage-level histograms and system-level tracing that exposes jitter sources you won’t see in application profiles.
Let’s get started.
OpenClaw Masterclass Workshop

Learn how to turn AI into a safe and cost-effective operational backbone with live case studies from experts who are running their business
Before we dive in…
On the morning of August 1, 2012, Knight Capital Group opened for trading as one of the largest market makers in the US, handling roughly 10% of all equity trading volume on American exchanges. By 10:15 AM, 45 minutes after the market opened, the firm had lost $440 million and was effectively finished as an independent company.
The cause was a software deployment error. A new version of Knight’s order routing system had been pushed to seven of its eight production servers. The eighth server, missed during deployment, continued running a dormant piece of code that had not been used since 2003. When the market opened, that server began firing child orders into the market at full speed to fill just 212 customer orders, and kept going. The system sent more than 4 million orders before anyone intervened. Ninety-seven automated alert emails had been generated referencing the error before the market even opened. And nobody even acted on them. (SEC enforcement order, October 2013)
Knight Capital did not fail because its engineers were careless or inexperienced. It failed because the engineering discipline required to run software at trading-system speeds was not matched to the speed at which the system could cause damage. That discipline covers deterministic deployment, observable behavior, and a tested kill path. In a system capable of sending thousands of orders per second, the gap between “something is wrong” and “the damage is done” is measured in minutes, not days.
This is what Shreyans Doshi addresses in his article.
🧠Expert Insight
From NIC to P99: Engineering Low-Latency C++ Trading Systems in 2026
by Shreyans Doshi
Trading systems have been evolving for decades, moving from manual execution based on charts and indicators to automated strategies that fire within tens of nanoseconds using FPGA and ASIC hardware. Both approaches still coexist today, but most advanced and systematic trading has moved into the sub-100 microsecond range. In this article I want to focus on the hardware and software aspects you need to understand in order to build a trading system with p95 wire-to-wire latency under 50 microseconds.
Traditional technology stacks like Java, JavaScript, TypeScript, and C# offer a lot of flexibility and scalability for large-scale applications, but their inherently nondeterministic nature makes it very difficult to get below a p50 latency of 500 microseconds. While there are ways to optimize garbage collection and other Java components for latency, most standard Java libraries do not focus on low-level concepts like aligning data to cache lines or reducing cache line misses. C and C++ applications optimize for a specific platform at the cost of portability, but that trade-off is exactly what gives you access to manual memory management and the ability to avoid multithreading pitfalls like false sharing. When the goal is to reduce latency, you need lower-level languages like C, C++, or Rust on critical paths. I will not cover pure hardware implementations like FPGAs or ASICs here since they are not required for our 50-microsecond latency target.
Important definitions
Before diving into the architecture and hardware optimizations, it will be helpful to establish exactly how performance is measured in a low-latency environment.
Wire-to-wire latency
Wire-to-wire latency is measured from the moment a market data packet is received on the NIC from the exchange to the moment an order is sent back to the exchange on the same NIC. You compute it as order send timestamp minus market data receive timestamp. The most precise measurements require NIC cards with hardware timestamping enabled, so the NIC stamps every inbound and outbound packet with a hardware timestamp that you can later use to analyze the latency graph. Exanic cards provide APIs for retrieving these hardware timestamps.
Assumptions about the system
To hit the latency target of under 50 microseconds, you need to optimize both hardware and server setup alongside your software, and the following assumptions underpin everything in this article.
Colocated host: Most stock exchanges in traditional finance provide colocation services where your servers sit physically adjacent to the exchange’s servers, removing extra network jitter from the equation.
UDP market data access: Most stock exchanges distribute market data via UDP multicast to all subscribed parties, and this is the fastest way to consume and react to it.
Kernel bypass NIC: The system runs on NIC cards enabled for kernel bypass and tuned for low-latency operation.
Single venue: These systems are single-venue, meaning at any point they process market data to generate orders for one stock exchange only. For multi-venue setups, the assumption is one colocated host per venue with no shared critical-path processing.
Workload model
Most trading systems follow this model of data processing in abstract terms.
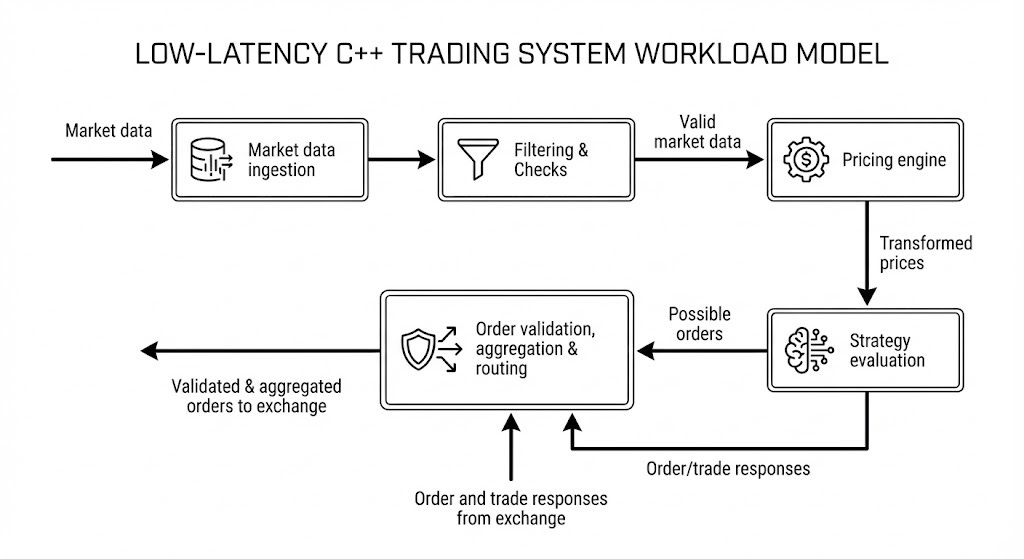
Every strategy engine takes market data from the exchange as its primary input and produces orders sent to the exchange as its primary output, moving through multiple stages as described below. Exchange responses are a secondary input to the engine but are not on the hot path for latency calculations.
Market data ingestion
The first layer is responsible for ingesting the market data (raw or normalized) from the network card. This layer routinely processes terabytes of data per day and can exceed a petabyte on busy days at venues like CME or Eurex. On an average day at CME you can expect 20 to 30 million trades and 100 to 150 million open interest events in a single segment. Processing a full L1 feed for one segment means receiving traffic in the range of a few terabytes to hundreds of terabytes per day, so both software and hardware need to be extremely optimized.
Filtering and checks
Filtering and checks come next, cleaning up incoming data and validating it before it reaches downstream stages. This layer handles packet drops, invalid market data, trading phase transitions like moving from an active session to a halted one, and anomalous price changes that might indicate a software bug. When something goes wrong at this stage, the right response is often to instruct strategies to stop rather than pass bad data forward.
Pricing engine
The pricing engine receives valid and normalized market data and can range from a simple no-op or currency conversion all the way to a full ML-powered model. Lightweight pricing fits comfortably on the critical path. Complex ML models that require large amounts of memory and processing do not, because they would blow the latency budget. In practice, ML-powered engines in low-latency applications split into two processes: time-consuming training and inference model preparation happen off the critical path, and a lightweight inference step runs on the critical path using small linearized models fed configuration parameters from the heavier ML output. This keeps the heavy lifting off the hot path while still giving the strategy access to model-driven signals. Colocation also constrains available compute, so you want to reserve it for work that directly impacts critical path performance.
Strategy evaluation
Strategy evaluation compares transformed or theoretical prices against real prices and fires an order when it identifies an opportunity. Strategies generally fall into three categories.
Maker: Maker strategies keep quotes on both the buy and sell sides to provide liquidity and take advantage of the bid-ask spread. Exchanges often provide incentives to HFT firms that add liquidity this way.
Taker: Taker strategies identify mispricing and fire IOC or FOK orders for immediate execution.
Hedging: Hedging strategies reduce risk or book profit by executing the opposite side of an existing position.
Order aggregation and routing (OMS)
Order aggregation and routing (OMS) can be combined with strategy evaluation in simple setups, but should be separated as complexity grows. It serves three purposes: aggregating orders from multiple strategies to reduce the number of orders sent to the exchange, managing exchange responses and passing normalized results back to the strategy, and handling the routing logic that grows more complex as your strategy count increases.
Latency map: where the latency lies
Now that the high-level components are clear, it is worth mapping out where the latency actually sits so you can allocate your budget with precision. Beyond the business logic itself, your latency profile depends on CPU model and generation, NIC type and model, operating system, software architecture, and business logic complexity.
Beyond the business logic stages, several factors contribute latency that stays invisible if you only look at application code. These factors come from hardware, OS and kernel processing, network behavior, and I/O, and they play an outsized role in ultra-low-latency systems. Even if they occur infrequently, they introduce jitter and latency spikes that directly hurt your p99. Although many of these latency sources depend on a multitude of factors, you can work with approximate cost ranges that provide a useful benchmark.
🛠️Tool of the Week
bpftrace — open-source high-level tracing language for Linux systems, built on eBPF
Highlights:
Instant latency visibility where it leaks: Attach probes to kernel/user-space events (kprobes/tracepoints/uprobes) to pinpoint tail-latency sources—scheduler delays, IRQ/softirq behavior, and “surprise” syscalls—without changing your C++ code.
Built-in distribution tooling (histograms by default): First-class aggregations like
hist()andquantize()make it trivial to generate p50/p95/p99-style views (not just averages), which is exactly what you need for jitter and p99 debugging.Ready-to-run scripts for common low-latency failure modes: The bundled
tools/library covers practical staples like syscall counts, run-queue latency, and retransmits—fast to deploy during an investigation, easy to keep as regression checks.
📎 Tech Briefs
PostgreSQL 18.3 / 17.9 / 16.13 / 15.17 / 14.22 released: PostgreSQL shipped an out-of-cycle patch set to all supported branches to fix regressions (including fixes touching standby behavior,
substring()encoding edge cases related to a CVE fix,pg_trgmstability, and restoringjson*_strip_nulls()immutability for index use).GitHub Actions: upload/download artifacts without forced ZIP: GitHub Actions added support to upload and download non-zipped artifacts (via
actions/upload-artifact@v7witharchive: falseandactions/download-artifact@v8), reducing friction for single-file downloads, in-browser viewing, and “double-zip” workflows.DPDK Governing Board minutes: quality-first 26.03 cycle + AI-assisted review gate): DPDK’s Feb 17 governing-board update highlights a code-hardening 26.03 cycle (roughly “half the commits” focused on fixes/backports) and describes introducing AI-assisted code reviews hosted by the UNH lab as an additional quality gate after standard CI passes.
Node.js 25.8.0 (Current) released: Node.js 25.8.0 landed with notable changes including SQLite
DatabaseSyncadditions, expanded diagnostics channel support, a new--permission-auditflag, and dependency updates (including an npm upgrade).Dependabot alert assignees GA: GitHub made Dependabot alert assignees generally available, enabling explicit ownership of dependency vulnerability alerts (UI + REST API + webhooks) and visibility across repo/org/enterprise alert views.
That’s all for today. Thank you for reading this issue of Deep Engineering.
We’ll be back next week with more expert-led content.
Stay awesome,
Saqib Jan
Editor-in-Chief, Deep Engineering
If your company is interested in reaching an audience of senior developers, software engineers, and technical decision-makers, you may want to advertise with us.
 |
|