

When to Use Object-Oriented Programming
The complete “Chapter 5: When to Use Object-Oriented Programming” from the book Python Object-Oriented Programming, Fourth Edition by Steven F. Lott and Dusty Phillips (Packt, July 2021).

In previous chapters, we've covered many of the defining features of object-oriented programming. We now know some principles and paradigms of object-oriented design, and we've covered the syntax of object-oriented programming in Python.
Yet, we don't know exactly how and, especially, when to utilize these principles and syntax in practice. In this chapter, we'll discuss some useful applications of the knowledge we've gained, looking at some new topics along the way:
How to recognize objects
Data and behaviors, once again
Wrapping data behaviors using properties
The Don't Repeat Yourself principle and avoiding repetition
In this chapter, we'll also address some alternative designs for our case study problem. We'll look at ways to partition the sample data into training sets and test sets.
We'll start this chapter with a close look at the nature of objects and their internal state. There are cases when there's no state change, and a class definition isn't desirable.
Treat objects as objects
This may seem obvious; you should generally give separate objects in your problem domain a special class in your code. We've seen examples of this in the case studies in previous chapters: first, we identify objects in the problem, and then model their data and behaviors.
Identifying objects is a very important task in object-oriented analysis and programming. But it isn't always as easy as counting the nouns in short paragraphs that, frankly, the authors have constructed explicitly for that purpose. Remember, objects are things that have both data and behavior. If we are working only with data, we are often better off storing it in a list, set, dictionary, or other Python data structure (which we'll be covering thoroughly in Chapter 7, Python Data Structures). On the other hand, if we are working only with behavior, but no stored data, a simple function is more suitable.
An object, however, has both data and behavior. Proficient Python programmers use built-in data structures unless (or until) there is an obvious need to define a class. There is no reason to add an extra level of complexity if it doesn't help organize our code. On the other hand, the need is not always self-evident.
We can often start our Python programs by storing data in a few variables. As the program expands, we will later find that we are passing the same set of related variables to a set of functions. This is the time to think about grouping both variables and functions into a class.
For example, if we are designing a program to model polygons in two-dimensional space, we might start with each polygon represented as a list of points. The points would be modeled as two tuples (x, y) describing where that point is located. This is all data, stored in a set of nested data structures (specifically, a list of tuples). We can (and often do) start hacking at the command prompt:
>>> square = [(1,1), (1,2), (2,2), (2,1)] Now, if we want to calculate the distance around the perimeter of the polygon, we need to sum the distances between each point. To do this, we need a function to calculate the distance between two points. Here are two such functions:
>>> from math import hypot
>>> def distance(p_1, p_2):
... return hypot(p_1[0]-p_2[0], p_1[1]-p_2[1])
>>> def perimeter(polygon):
... pairs = zip(polygon, polygon[1:]+polygon[:1])
... return sum(
... distance(p1, p2) for p1, p2 in pairs
... )We can exercise the functions to check our work:
>>> perimeter(square)
4.0This is a start, but it's not completely descriptive of the problem domain. We can kind of see what a polygon might be. But we need to read the entire batch of code to see how the two functions work together.
We can add type hints to help clarify the intent behind each function. The result looks like this:
from __future__ import annotations
from math import hypot
from typing import Tuple, List
Point = Tuple[float, float]
def distance(p_1: Point, p_2: Point) -> float:
return hypot(p_1[0] - p_2[0], p_1[1] - p_2[1])
Polygon = List[Point]
def perimeter(polygon: Polygon) -> float:
pairs = zip(polygon, polygon[1:] + polygon[:1])
return sum(distance(p1, p2) for p1, p2 in pairs)We've added two type definitions, Point and Polygon, to help clarify our intentions. The definition of Point shows how we'll use the built-in tuple class. The definition of Polygon shows how the built-in list class builds on the Point class.
When writing annotations inside method parameter definitions, we can generally use the type name directly, for example, def method(self, values: list[int]) -> None:. For this to work, we need to use from __future__ import annotations. When defining a new type hint, however, we need to use the names from the typing module. That's why the definition of the new Point type uses typing.Tuple in the expression Tuple[float, float].
Now, as object-oriented programmers, we clearly recognize that a polygon class could encapsulate the list of points (data) and the perimeter function (behavior). Further, a Point class, such as we defined in Chapter 2, Objects in Python, might encapsulate the x and y coordinates and the distance method. The question is: is it valuable to do this?
For the previous code, maybe yes, maybe no. With our recent experience in object-oriented principles, we can write an object-oriented version in record time. Let's compare them as follows:
from math import hypot
from typing import Tuple, List, Optional, Iterable
class Point:
def __init__(self, x: float, y: float) -> None:
self.x = x
self.y = y
def distance(self, other: "Point") -> float:
return hypot(self.x - other.x, self.y - other.y)
class Polygon:
def __init__(self) -> None:
self.vertices: List[Point] = []
def add_point(self, point: Point) -> None:
self.vertices.append((point))
def perimeter(self) -> float:
pairs = zip(
self.vertices, self.vertices[1:] + self.vertices[:1])
return sum(p1.distance(p2) for p1, p2 in pairs)There seems to be almost twice as much code here as there was in our earlier version, although we could argue that the add_point method is not strictly necessary. We could also try to insist on using _vertices to discourage the use of the attribute, but the use of leading _ variable names doesn't seem to really solve the problem.
Now, to understand the differences between the two classes a little better, let's compare the two APIs in use. Here's how to calculate the perimeter of a square using the object-oriented code:
>>> square = Polygon()
>>> square.add_point(Point(1,1))
>>> square.add_point(Point(1,2))
>>> square.add_point(Point(2,2))
>>> square.add_point(Point(2,1))
>>> square.perimeter()
4.0That's fairly succinct and easy to read, you might think, but let's compare it to the function-based code:
>>> square = [(1,1), (1,2), (2,2), (2,1)]
>>> perimeter(square)
4.0Hmm, maybe the object-oriented API isn't so compact! Our first, hacked-in version, without type hints or class definitions, is the shortest. How do we know what the list of tuples is supposed to represent? How do we remember what kind of object we're supposed to pass into the perimeter function? We needed some documentation to explain how the first set of functions should be used.
The functions annotated with type hints were quite a bit easier to understand, as were the class definitions. The relationships among the objects are more clearly defined by hints or classes or both.
Code length is not a good indicator of code complexity. Some programmers get hung up on complicated one-liners that do an incredible amount of work in one line of code. This can be a fun exercise, but the result is often unreadable, even to the original author the following day. Minimizing the amount of code can often make a program easier to read, but do not blindly assume this is the case.
No one wins at code golf. Minimizing the volume of code is rarely desirable.
Luckily, this trade-off isn't necessary. We can make the object-oriented Polygon API as easy to use as the functional implementation. All we have to do is alter our Polygon class so that it can be constructed with multiple points.
Let's give it an initializer that accepts a list of Point objects:
class Polygon_2:
def __init__(self, vertices: Optional[Iterable[Point]] = None) -> None:
self.vertices = list(vertices) if vertices else []
def perimeter(self) -> float:
pairs = zip(
self.vertices, self.vertices[1:] + self.vertices[:1])
return sum(p1.distance(p2) for p1, p2 in pairs)For the perimeter() method, we've used the zip() function to create pairs of vertices, with items drawn from two lists to create a sequence of pairs. One list provided to zip() is the complete sequence of vertices. The other list of vertices starts from vertex 1 (not 0) and ends with the vertex before 1 (that is, vertex 0). For a triangle, this will make three pairs: (v[0], v[1]), (v[1], v[2]), and (v[2], v[0]). We can then compute the distance between the pairs using Point.distance(). Finally, we sum the sequence of distances. This seems to improve things considerably. We can now use this class like the original hacked-in function definitions:
>>> square = Polygon_2(
... [Point(1,1), Point(1,2), Point(2,2), Point(2,1)]
... )
>>> square.perimeter()
4.0
It's handy to have the details of the individual method definitions. We've built an API that's close to the original, succinct set of definitions. We've added enough formality to be confident the code is likely to work before we even start putting test cases together.
Let's take one more step. Let's allow it to accept tuples too, and we can construct the Point objects ourselves, if needed:
Pair = Tuple[float, float]
Point_or_Tuple = Union[Point, Pair]
class Polygon_3:
def __init__(self, vertices: Optional[Iterable[Point_or_Tuple]] = None) -> None:
self.vertices: List[Point] = []
if vertices:
for point_or_tuple in vertices:
self.vertices.append(self.make_point(point_or_tuple))
@staticmethod
def make_point(item: Point_or_Tuple) -> Point:
return item if isinstance(item, Point) else Point(*item)This initializer goes through the list of items (either Point or Tuple[float, float]) and ensures that any non-Point objects are converted to Point instances.
If you are experimenting with the above code, you should also define these variant class designs by creating subclasses of Polygon and overriding the __init__() method. Extending a class with dramatically different method signatures can raise error flags from mypy.
For an example this small, there's no clear winner between the object-oriented and more data-oriented versions of this code. They all do the same thing. If we have new functions that accept a polygon argument, such as area(polygon) or point_in_polygon(polygon, x, y), the benefits of the object-oriented code become increasingly obvious. Likewise, if we add other attributes to the polygon, such as color or texture, it makes more and more sense to encapsulate that data into a single class.
The distinction is a design decision, but in general, the more important a set of data is, the more likely it is to have multiple functions specific to that data, and the more useful it is to use a class with attributes and methods instead.
When making this decision, it also pays to consider how the class will be used. If we're only trying to calculate the perimeter of one polygon in the context of a much greater problem, using a function will probably be quickest to code and easier to use one time only. On the other hand, if our program needs to manipulate numerous polygons in a wide variety of ways (calculating the perimeter, area, and intersection with other polygons, moving or scaling them, and so on), we have almost certainly identified a class of related objects. The class definition becomes more important as the number of instances increases.
Additionally, pay attention to the interaction between objects. Look for inheritance relationships; inheritance is impossible to model elegantly without classes, so make sure to use them. Look for the other types of relationships we discussed in Chapter 1, Object-Oriented Design, association and composition.
Composition can, technically, be modeled using only data structures – for example, we can have a list of dictionaries holding tuple values – but it is sometimes less complicated to create a few classes of objects, especially if there is behavior associated with the data.
One size does not fit all. The built-in, generic collections and functions work well for a large number of simple cases. A class definition works well for a large number of more complex cases. The boundary is hazy at best.
Adding behaviors to class data with properties
Throughout this book, we've focused on the separation of behavior and data. This is very important in object-oriented programming, but we're about to see that, in Python, the distinction is uncannily blurry. Python is very good at blurring distinctions; it doesn't exactly help us to think outside the box. Rather, it teaches us to stop thinking about the box.
Before we get into the details, let's discuss some bad object-oriented design principles. Many object-oriented developers teach us to never access attributes directly. They insist that we write attribute access like this:
class Color:
def __init__(self, rgb_value: int, name: str) -> None:
self._rgb_value = rgb_value
self._name = name
def set_name(self, name: str) -> None:
self._name = name
def get_name(self) -> str:
return self._name
def set_rgb_value(self, rgb_value: int) -> None:
self._rgb_value = rgb_value
def get_rgb_value(self) -> int:
return self._rgb_valueThe instance variables are prefixed with an underscore to suggest that they are private (other languages would actually force them to be private). Then, the get and set methods provide access to each variable. This class would be used in practice as follows:
>>> c = Color(0xff0000, "bright red")
>>> c.get_name()
'bright red'
>>> c.set_name("red")
>>> c.get_name()
'red'The above example is not nearly as readable as the direct access version that Python favors:
class Color_Py:
def __init__(self, rgb_value: int, name: str) -> None:
self.rgb_value = rgb_value
self.name = nameHere's how this class works. It's slightly simpler:
>>> c = Color_Py(0xff0000, "bright red")
>>> c.name
'bright red'
>>> c.name = "red"
>>> c.name
'red'So, why would anyone insist upon the method-based syntax?
The idea of setters and getters seems helpful for encapsulating the class definitions. Some Java-based tools can generate all the getters and setters automagically, making them almost invisible. Automating their creation doesn't make them a great idea. The most important historical reason for having getters and setters was to make the separate compilation of binaries work out in a tidy way. Without a need to link separately compiled binaries, this technique doesn't always apply to Python.
One ongoing justification for getters and setters is that, someday, we may want to add extra code when a value is set or retrieved. For example, we could decide to cache a value to avoid complex computations, or we might want to validate that a given value is a suitable input.
For example, we could decide to change the set_name() method as follows:
class Color_V:
def __init__(self, rgb_value: int, name: str) -> None:
self._rgb_value = rgb_value
if not name:
raise ValueError(f"Invalid name {name!r}")
self._name = name
def set_name(self, name: str) -> None:
if not name:
raise ValueError(f"Invalid name {name!r}")
self._name = nameIf we had written our original code for direct attribute access, and then later changed it to a method like the preceding one, we'd have a problem: anyone who had written code that accessed the attribute directly would now have to change their code to access a method. If they didn't then change the access style from attribute access to a function call, their code would be broken.
The mantra that we should make all attributes private, accessible through methods, doesn't make much sense in Python. The Python language lacks any real concept of private members! We can see the source; we often say "We're all adults here." What can we do? We can make the syntax distinction between attribute and method less visible.
Python gives us the property function to make methods that look like attributes. We can therefore write our code to use direct member access, and if we ever unexpectedly need to alter the implementation to do some calculation when getting or setting that attribute's value, we can do so without changing the interface. Let's see how it looks:
class Color_VP:
def __init__(self, rgb_value: int, name: str) -> None:
self._rgb_value = rgb_value
if not name:
raise ValueError(f"Invalid name {name!r}")
self._name = name
def _set_name(self, name: str) -> None:
if not name:
raise ValueError(f"Invalid name {name!r}")
self._name = name
def _get_name(self) -> str:
return self._name
name = property(_get_name, _set_name)Compared to the earlier class, we first change the name attribute into a (semi-)private _name attribute. Then, we add two more (semi-)private methods to get and set that variable, performing our validation when we set it.
Finally, we have the property construction at the bottom. This is the Python magic. It creates a new attribute on the Color class called name. It sets this attribute to be a property. Under the hood, a property attribute delegates the real work to the two methods we just created. When used in an access context (on the right side of the = or :=), the first function gets the value. When used in an update context (on the left side of = or :=), the second function sets the value.
This new version of the Color class can be used in exactly the same way as the earlier version, yet it now performs validation when we set the name attribute:
>>> c = Color_VP(0xff0000, "bright red")
>>> c.name
'bright red'
>>> c.name = "red"
>>> c.name
'red'
>>> c.name = ""
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "setting_name_property.py", line 8, in _set_name
raise ValueError(f"Invalid name {name!r}")
ValueError: Invalid name ''So, if we'd previously written code to access the name attribute, and then changed it to use our property-based object, the previous code would still work. If it attempts to set an empty property value, this is behavior we wanted to forbid. Success!
Bear in mind that, even with the name property, the previous code is not 100% safe. People can still access the _name attribute directly and set it to an empty string if they want to. But if they access a variable we've explicitly marked with an underscore to suggest it is private, they're the ones that have to deal with the consequences, not us. We established a formal contract, and if they elect to break the contract, they own the consequences.
Properties in detail
Think of the property function as returning an object that proxies any requests to get or set the attribute value through the method names we have specified. The property built-in is like a constructor for such an object, and that object is set as the public-facing member for the given attribute.
This property constructor can actually accept two additional arguments, a delete function and a docstring for the property. The delete function is rarely supplied in practice, but it can be useful for logging the fact that a value has been deleted, or possibly to veto deleting if we have reason to do so. The docstring is just a string describing what the property does, no different from the docstrings we discussed in Chapter 2, Objects in Python. If we do not supply this parameter, the docstring will instead be copied from the docstring for the first argument: the getter method.
Here is a silly example that states whenever any of the methods are called:
class NorwegianBlue:
def __init__(self, name: str) -> None:
self._name = name
self._state: str
def _get_state(self) -> str:
print(f"Getting {self._name}'s State")
return self._state
def _set_state(self, state: str) -> None:
print(f"Setting {self._name}'s State to {state!r}")
self._state = state
def _del_state(self) -> None:
print(f"{self._name} is pushing up daisies!")
del self._state
silly = property(
_get_state, _set_state, _del_state,
"This is a silly property")Note that the state attribute has a type hint, str, but no initial value. It can be deleted, and only exists for part of the life of a NorwegianBlue. We need to provide a hint to help mypy understand what the type should be. But we don't assign a default value because that's the job of the setter method.
If we actually use an instance of this class, it does indeed print out the correct strings when we ask it to:
>>> p = NorwegianBlue("Polly")
>>> p.silly = "Pining for the fjords"
Setting Polly's State to 'Pining for the fjords'
>>> p.silly
Getting Polly's State
'Pining for the fjords'
>>> del p.silly
Polly is pushing up daisies!Further, if we look at the help text for the Silly class (by issuing help(Silly) at the interpreter prompt), it shows us the custom docstring for our silly attribute:
Help on class NorwegianBlue in module colors:
class NorwegianBlue(builtins.object)
| NorwegianBlue(name: str) -> None
|
| Methods defined here:
|
| __init__(self, name: str) -> None
| Initialize self. See help(type(self)) for accurate signature.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| silly
| This is a silly propertyOnce again, everything is working as we planned. In practice, properties are normally only defined with the first two parameters: the getter and setter functions. If we want to supply a docstring for a property, we can define it on the getter function; the property proxy will copy it into its own docstring. The delete function is often left empty because object attributes are so rarely deleted.
Decorators – another way to create properties
We can create properties using decorators. This makes the definitions easier to read. Decorators are a ubiquitous feature of Python syntax, with a variety of purposes. For the most part, decorators modify the function definition that they precede. We'll look at the decorator design pattern more broadly in Chapter 11, Common Design Patterns.
The property function can be used with the decorator syntax to turn a get method into a property attribute, as follows:
class NorwegianBlue_P:
def __init__(self, name: str) -> None:
self._name = name
self._state: str
@property
def silly(self) -> str:
print(f"Getting {self._name}'s State")
return self._stateThis applies the property function as a decorator to the function that follows. It is equivalent to the previous silly = property(_get_state) syntax. The main difference, from a readability perspective, is that we get to mark the silly method as a property at the top of the method, instead of after it is defined, where it can be easily overlooked. It also means we don't have to create private methods with underscore prefixes just to define a property.
Going one step further, we can specify a setter function for the new property as follows:
class NorwegianBlue_P:
def __init__(self, name: str) -> None:
self._name = name
self._state: str
@property
def silly(self) -> str:
"""This is a silly property"""
print(f"Getting {self._name}'s State")
return self._state
@silly.setter
def silly(self, state: str) -> None:
print(f"Setting {self._name}'s State to {state!r}")
self._state = stateThis syntax, @silly.setter, looks odd compared with @property, although the intent should be clear. First, we decorate the silly method as a getter. Then, we decorate a second method with exactly the same name by applying the setter attribute of the originally decorated silly method! This works because the property function returns an object; this object also has its own setter attribute, which can then be applied as a decorator to other methods. Using the same name for the get and set methods helps to group together the multiple methods that access one common attribute.
We can also specify a delete function with @silly.deleter. Here's what it looks like:
@silly.deleter
def silly(self) -> None:
print(f"{self._name} is pushing up daisies!")
del self._stateWe cannot specify a docstring using property decorators, so we need to rely on the decorator copying the docstring from the initial getter method. This class operates exactly the same as our earlier version, including the help text. You'll see the decorator syntax in widespread use. The function syntax is how it actually works under the hood.
Deciding when to use properties
With the built-in property blurring the division between behavior and data, it can be confusing to know when to choose an attribute, or a method, or a property. In the Color_VP class example we saw earlier, we added argument value validation to setting an attribute. In the NorwegianBlue class example, we wrote detailed log entries when attributes were set and deleted. There are also other factors to take into account when deciding to use a property.
In Python, data, properties, and methods are all attributes of a class. The fact that a method is callable does not distinguish it from other types of attributes; indeed, we'll see in Chapter 8, The Intersection of Object-Oriented and Functional Programming, that it is possible to create normal objects that can be called like functions. We'll also discover that functions and methods are themselves ordinary objects.
The fact that methods are callable attributes, and properties are also attributes, can help us make this decision. We suggest the following principles:
Use methods to represent actions; things that can be done to, or performed by, the object. When you call a method, even with only one argument, it should do something. Method names are generally verbs.
Use attributes or properties to represent the state of the object. These are the nouns, adjectives, and prepositions that describe an object.
Default to ordinary (non-property) attributes, initialized in the
__init__()method. These must be computed eagerly, which is a good starting point for any design.Use properties for attributes in the exceptional case when there's a computation involved with setting or getting (or deleting) an attribute. Examples include data validation, logging, and access controls. We'll look at cache management in a moment. We can also use properties for lazy attributes, where we want to defer the computation because it's costly and rarely needed.
Let's look at a more realistic example. A common need for custom behavior is caching a value that is difficult to calculate or expensive to look up (requiring, for example, a network request or database query). The goal is to store the value locally to avoid repeated calls to the expensive calculation.
We can do this with a custom getter on the property. The first time the value is retrieved, we perform the lookup or calculation. Then, we can locally cache the value as a private attribute on our object (or in dedicated caching software), and the next time the value is requested, we return the stored data. Here's how we might cache a web page:
from urllib.request import urlopen
from typing import Optional, cast
class WebPage:
def __init__(self, url: str) -> None:
self.url = url
self._content: Optional[bytes] = None
@property
def content(self) -> bytes:
if self._content is None:
print("Retrieving New Page...")
with urlopen(self.url) as response:
self._content = response.read()
return self._contentWe'll only read the website content once, when self._content has the initial value of None. After that, we'll return the value most recently read for the site. We can test this code to see that the page is only retrieved once:
import time
webpage = WebPage("http://ccphillips.net/")
now = time.perf_counter()
content1 = webpage.content
first_fetch = time.perf_counter() - now
now = time.perf_counter()
content2 = webpage.content
second_fetch = time.perf_counter() - now
assert content2 == content1, "Problem: Pages were different"
print(f"Initial Request {first_fetch:.5f}")
print(f"Subsequent Requests {second_fetch:.5f}")The output?
% python src/colors.py
Retrieving New Page...
Initial Request 1.38836
Subsequent Requests 0.00001It took about 1.388 seconds to retrieve a page from the ccphilips.net web host. The second fetch – from a laptop's RAM – takes 0.01 milliseconds! This is sometimes written as 10 μs, 10 microseconds. Since this is the last digit, we can suspect it's subject to rounding, and the time may be only half that, perhaps as little as 5 μs.
Custom getters are also useful for attributes that need to be calculated on the fly, based on other object attributes. For example, we might want to calculate the average for a list of integers:
class AverageList(List[int]):
@property
def average(self) -> float:
return sum(self) / len(self)This small class inherits from list, so we get list-like behavior for free. We added a property to the class, and – hey, presto! – our list can have an average as follows:
>>> a = AverageList([10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5])
>>> a.average
9.0Of course, we could have made this a method instead, but if we do, then we ought to call it calculate_average(), since methods represent actions. But a property called average is more suitable, and is both easier to type and easier to read.
We can imagine a number of similar reductions, including minimum, maximum, standard deviation, median, and mode, all being properties of a collection of numbers. This can simplify a more complex analysis by encapsulating these summaries into the collection of data values.
Custom setters are useful for validation, as we've already seen, but they can also be used to proxy a value to another location. For example, we could add a content setter to the WebPage class that automatically logs into our web server and uploads a new page whenever the value is set.
Manager objects
We've been focused on objects and their attributes and methods. Now, we'll take a look at designing higher-level objects; the kind of objects that manage other objects – the objects that tie everything together. These are sometimes called Façade objects because they present a pleasant, easy-to-use façade over some underlying complexity. See Chapter 12, Advanced Design Patterns, for an additional look at the Façade design pattern.
Most of the previous examples tend to model concrete ideas. Management objects are more like office managers; they don't do the actual visible work out on the floor, but without them, there would be no communication between departments, and nobody would know what they are supposed to do (although, this can be true anyway if the organization is badly managed!). Analogously, the attributes on a management class tend to refer to other objects that do the visible work; the behaviors on such a class delegate to those other classes at the right time, and pass messages between them.
A manager relies on composite design. We assemble a manager class by knitting other objects together. The overall behavior of the manager emerges from the interaction of objects. To an extent, a manager is also an Adapter among the various interfaces. See Chapter 12, Advanced Design Patterns, for an additional look at the Adapter design pattern.
As an example, we'll write a program that does a find-and-replace action for text files stored in a compressed archive file, either a ZIP archive or a TAR archive. We'll need objects to represent the archive file as a whole and each individual text file (luckily, we don't have to write these classes, as they're available in the Python standard library).
An overall manager object will be responsible for ensuring the following three steps occur:
Unzipping the compressed file to examine each member
Performing the find-and-replace action on text members
Zipping up the new files with the untouched as well as changed members
Note that we have to choose between an eager and a lazy approach to the three steps of this process. We can eagerly unzip (or untar) the entire archive, process all the files, and then build a new archive. This tends to use a lot of disk space. An alternative is to lazily extract items one at a time from the archive, perform the find-and-replace, and then build a new compressed archive as we go. The lazy approach doesn't require as much storage.
This design will knit together elements of the pathlib, zipfile, and the regular expression (re) module. The initial design will be focused on the job at hand. Later in this chapter, we'll rethink this design as new requirements surface.
The class is initialized with the archive file's name. We don't do anything else upon creation. We'll define a method with a good, clear verb in its name that does any processing:
from __future__ import annotations
import fnmatch
from pathlib import Path
import re
import zipfile
class ZipReplace:
def __init__(
self,
archive: Path,
pattern: str,
find: str,
replace: str
) -> None:
self.archive_path = archive
self.pattern = pattern
self.find = find
self.replace = replaceGiven the archive, the filename pattern to match, and the strings to work with, the object will have everything it needs. We might provide arguments like ZipReplace(Path("sample.zip"), "*.md", "xyzzy", "xyzzy").
The overall manager method for the find-and-replace operation revises a given archive. This method of the ZipReplace class (started above) uses two other methods and delegates most of the real work to other objects:
def find_and_replace(self) -> None:
input_path, output_path = self.make_backup()
with zipfile.ZipFile(output_path, "w") as output:
with zipfile.ZipFile(input_path) as input:
self.copy_and_transform(input, output)The make_backup() method will use the pathlib module to rename the old ZIP file so it's obviously the backup copy, untouched. This backup copy is input to the copy_and_transform() method. The original name will be the final output, also. This makes it look like the file was updated "in place." In fact, a new file was created, but the old name will be assigned to the new content.
We create two context managers (a special kind of manager) to control the open files. An open file is entangled with operating system resources. In the case of a ZIP file or TAR archive, there are summaries and checksums that need to be properly written when the file is closed. Using a context manager assures that this additional work is done, and done properly, in spite of any exceptions being raised. All file operations should be wrapped in a with statement to leverage Python's context manager and handle proper cleanup. We'll look at this again in Chapter 9, Strings, Serialization, and File Paths.
The copy_and_transform() method uses methods of the two ZipFile instances and the re module to transform members of the original file. Since a backup was made of the original file, this will build the output file from the backup file. It examines each member of the archive, performing a number of steps, including expanding the compressed data, doing the transformation with a transform() method, and compressing to write to the output file, and then cleaning up the temporary file (and directories).
Obviously, we could do all of these steps in one method of a class, or indeed do the whole thing in one complex script, without ever creating an object. There are several advantages to separating the steps:
Readability: The code for each step is in a self-contained unit that is easy to read and understand. The method name describes what the method does, and less additional documentation is required to understand what is going on.
Extensibility: If a subclass wanted to use compressed TAR files instead of ZIP files, it could override the
copy_and_transform()method, reusing all the supporting methods because they apply to any file irrespective of the kind of archive.Partitioning: An external class could create an instance of this class and use
make_backup()or thecopy_and_transform()methods directly, bypassing thefind_and_replace()manager.
These two methods of the ZipReplace class (started above) make the backup copy and create the new file by reading from the backup and writing new items after they've been modified:
def make_backup(self) -> tuple[Path, Path]:
input_path = self.archive_path.with_suffix(
f"{self.archive_path.suffix}.old")
output_path = self.archive_path
self.archive_path.rename(input_path)
return input_path, output_path
def copy_and_transform(
self, input: zipfile.ZipFile, output: zipfile.ZipFile
) -> None:
for item in input.infolist():
extracted = Path(input.extract(item))
if (not item.is_dir()
and fnmatch.fnmatch(item.filename, self.pattern)):
print(f"Transform {item}")
input_text = extracted.read_text()
output_text = re.sub(self.find, self.replace, input_text)
extracted.write_text(output_text)
else:
print(f"Ignore {item}")
output.write(extracted, item.filename)
extracted.unlink()
for parent in extracted.parents:
if parent == Path.cwd():
break
parent.rmdir()The make_backup() method applies a common strategy to avoid damaging a file. The original file is renamed to preserve it, and a new file is created that will have the original file's name. This method is designed to be independent of the file type or other processing details.
The copy_and_transform() function method builds the new archive out of members extracted from the original archive. It performs a number of steps for each member of the archive:
Extract this file from the original archive.
If the item is not a directory (this is unlikely, but still possible), and the name matches the wild-card pattern, we want to transform it. This is a three-step process.
Read the file's text.
Transform the file, using the
sub()function of theremodule.Write the text, replacing the extracted file. This is where we create a copy of the content.
Compress the file – either an untouched file or a transformed file – into the new archive.
We unlink the temporary copy. If there are no links left to the file, it will be deleted by the operating system.
We clean up any temporary directories created by the extraction process.
The
copy_and_transform()method's operations span thepathlib,zipfile, andremodules. Wrapping these operations up into a manager that uses context managers gives us a tidy package with a small interface.
We can create a main script to use the ZipReplace class:
if __name__ == "__main__":
sample_zip = Path("sample.zip")
zr = ZipReplace(sample_zip, "*.md", "xyzzy", "plover's egg")
zr.find_and_replace()We've provided the archive (sample.zip), the file matching pattern (*.md), the string to replace (xyzzy), and the final replacement (plover's egg). This will perform a complex series of file operations. A more practical approach is to use the argparse module to define the command-line interface (CLI) for this application.
For brevity, the details are sparsely documented. Our current focus is on object-oriented design; if you are interested in the inner details of the zipfile module, refer to the documentation in the standard library, either online or by typing import zipfile and help(zipfile) into your interactive interpreter.
Of course, an instance of the ZipReplace class does not have to be created from the command line; our class could be imported into another module (to perform batch ZIP file processing), or accessed as part of a GUI interface or even a higher-level manager object that knows where to get ZIP files (for example, to retrieve them from an FTP server or back them up to an external disk).
The benefit of the Façade and Adapter design patterns is to encapsulate complexity into a more useful class design. These composite objects tend to be less like physical objects, and enter the realm of conceptual objects. When we step away from objects that have a close parallel with the real world, the methods are actions that change the state of those concepts; care is required because the simple analogies start to disappear in the haze of ideas. It helps when the foundation is a set of concrete data values and well-defined behaviors.
A good example to bear in mind is the World Wide Web. A web server provides content to browsers. The content can include JavaScript that behaves like a desktop application which reaches out to other web servers to present content. These conceptual relationships are implemented by tangible transfers of bytes. It also includes a browser to paint pages of text, images, video, or sound. The foundation is transfers of bytes, a tangible action. In a classroom setting, it's possible to have developers pass sticky notes and rubber balls to each other to represent requests and responses.
This example works nicely. When we're confronted with additional requirements, we need to find a way to build new, related features without duplicating code. We'll talk about this engineering imperative first, then look at the revised design.
Removing duplicate code
Often, the code in management-style classes such as ZipReplace is quite generic and can be applied in a variety of ways. It is possible to use either composition or inheritance to help keep this code in one place, thus eliminating duplicate code. Before we look at any examples of this, let's discuss some design principles. Specifically, why is duplicate code a bad thing?
There are several reasons, but they all boil down to readability and maintainability. When we're writing a new piece of code that is similar to an earlier piece, the easiest thing to do is copy and paste the old code and change whatever needs to be changed (variable names, logic, comments) to make it work in the new location. Alternatively, if we're writing new code that seems similar, but not identical, to code elsewhere in the project, it is often easier to write fresh code with similar behavior, rather than figuring out how to extract the overlapping functionality. We sometimes call this copy-pasta programming because the result is a big mass of tangled noodles of code, like a bowl of spaghetti.
But as soon as someone trying to understand the code comes across duplicate (or nearly duplicate) code blocks, they now have an additional barrier to understanding. There's an intellectual friction created by a number of side-bar questions. Are they truly identical? If not, how is one section different from the other? What parts are the same? Under what conditions is one section called? When do we call the other? You might argue that you're the only one reading your code, but if you don't touch that code for eight months, it will be as incomprehensible to you as it is to a fresh coder. When we're trying to read two similar pieces of code, we have to understand why they're different, as well as how they're different. This wastes the reader's time; code should always be written to be readable first.
[Dusty here, stepping out of formal author mode] I once had to try to understand someone's code that had three identical copies of the same 300 lines of very poorly written code. I had been working with the code for a month before I finally comprehended that the three identical versions were actually performing slightly different tax calculations. Some of the subtle differences were intentional, but there were also obvious areas where someone had updated a calculation in one function without updating the other two. The number of subtle, incomprehensible bugs in the code could not be counted. I eventually replaced all 900 lines with an easy-to-read function of 20 lines or so.
As the preceding story suggests, keeping two similar pieces of code up to date can be a nightmare. We have to remember to update both sections whenever we update one of them, and we have to remember how multiple sections differ so we can modify our changes when we are editing each of them. If we forget to update all sections, we will end up with extremely annoying bugs that usually manifest themselves as: "But I fixed that already, why is it still happening?"
The key factor here is the time spent in troubleshooting, maintenance, and enhancement compared with the time spent initially creating the code. Software that's in use for more than a few weeks will have a lot more eyeballs on it than the time spent creating it. The tiny bit of time we "save" by copying and pasting existing code is more than wasted when we have to maintain it.
One of the author's personal bests was an application that was in use for almost seventeen years. If other developers and users wasted one extra day each year trying to sort out some confusing part of the code, it means the author should have spent at least two more weeks improving the code to head off this future maintenance cost.
Code is both read and modified many more times and much more often than it is written. Comprehensible code should always be a priority.
This is why programmers, especially Python programmers (who tend to value elegant code more than average developers), follow what is known as the Don't Repeat Yourself (DRY) principle. Our advice for beginner programmers is to never use the copy-and-paste feature of their editor. To intermediate programmers: think thrice before hitting Ctrl + C.
But what should we do instead of code duplication? The simplest solution is often to move the code into a function that accepts parameters to account for whatever parts are different. This isn't a strictly object-oriented solution, but it is frequently optimal.
For example, if we have two pieces of code that unzip a ZIP file into two different directories, we can easily replace it with a function that accepts a parameter for the directory to which it should be unzipped. This may make the function itself slightly longer. The size of a function – measured as lines of code – isn't a good metric for readability. No one wins at code golf.
Good names and docstrings are essential. Each class, method, function, variable, property, attribute, module, and package name should be chosen thoughtfully. When writing docstrings, don't explain how the code works (the code should do that). Be sure to focus on what the code's purpose is, what the preconditions are for using it, and what will be true after the function or method has been used.
The moral of the story is: always make the effort to refactor your code to be easier to read, instead of writing bad code that may seem easier to write. Now we can look at the revised design to the ZipReplace class definition.
In practice
Let's explore two ways we can reuse our existing code. After writing our code to replace strings in a ZIP file full of text files, we are later contracted to scale all the images in a ZIP file to a size suitable for mobile devices. While resolutions vary, 640 x 960 is about the smallest we need. It looks like we could use a very similar paradigm to what we used in ZipReplace.
Our first impulse might be to save a copy of that module and change the find_replace method to scale_image or something similar in the copy.
This processing will rely on the Pillow library to open an image file, scale it, and save it. The Pillow image processing tools can be installed with the following command:
% python -m pip install pillowThis will provide some great image-processing tools.
As we noted above in the Removing duplicate code section of this chapter, this copy-and-paste programming approach is suboptimal. What if someday we want to change the unzip and zip methods to also open TAR files? Or maybe we'll want to use a guaranteed unique directory name for temporary files. In either case, we'd have to change it in two different places!
We'll start by demonstrating an inheritance-based solution to this problem. First, we'll modify our original ZipReplace class into a superclass for processing ZIP files in a variety of ways:
from abc import ABC, abstractmethod
class ZipProcessor(ABC):
def __init__(self, archive: Path) -> None:
self.archive_path = archive
self._pattern: str
def process_files(self, pattern: str) -> None:
self._pattern = pattern
input_path, output_path = self.make_backup()
with zipfile.ZipFile(output_path, "w") as output:
with zipfile.ZipFile(input_path) as input:
self.copy_and_transform(input, output)
def make_backup(self) -> tuple[Path, Path]:
input_path = self.archive_path.with_suffix(
f"{self.archive_path.suffix}.old")
output_path = self.archive_path
self.archive_path.rename(input_path)
return input_path, output_path
def copy_and_transform(
self, input: zipfile.ZipFile, output: zipfile.ZipFile
) -> None:
for item in input.infolist():
extracted = Path(input.extract(item))
if self.matches(item):
print(f"Transform {item}")
self.transform(extracted)
else:
print(f"Ignore {item}")
output.write(extracted, item.filename)
self.remove_under_cwd(extracted)
def matches(self, item: zipfile.ZipInfo) -> bool:
return (
not item.is_dir()
and fnmatch.fnmatch(item.filename, self._pattern))
def remove_under_cwd(self, extracted: Path) -> None:
extracted.unlink()
for parent in extracted.parents:
if parent == Path.cwd():
break
parent.rmdir()
@abstractmethod
def transform(self, extracted: Path) -> None:
...We dropped the three parameters to __init__(), pattern, find, and replace, that were specific to ZipReplace. Then, we renamed the find_replace() method to process_files(). We decomposed the complex copy_and_transform() method and made it call several other methods to do the real work. This includes a placeholder for a transform() method. These name changes help demonstrate the more generalized nature of our new class.
This new ZipProcessor class is a subclass of ABC, an abstract base class, allowing us to provide placeholders instead of methods. (More on ABCs to come in Chapter 6, Abstract Base Classes and Operator Overloading.) This abstract class doesn't actually define a transform() method. If we try to create an instance of the ZipProcessor class, the missing transform() method will raise an exception. The formality of an @abstractmethod decoration makes it clear that there's a piece missing, and the piece must have the expected shape.
Now, before we move on to our image processing application, let's create a version of our original ZipReplace class. This will be based on the ZipProcessor class to make use of this parent class, as follows:
class TextTweaker(ZipProcessor):
def __init__(self, archive: Path) -> None:
super().__init__(archive)
self.find: str
self.replace: str
def find_and_replace(self, find: str, replace: str) -> "TextTweaker":
self.find = find
self.replace = replace
return self
def transform(self, extracted: Path) -> None:
input_text = extracted.read_text()
output_text = re.sub(self.find, self.replace, input_text)
extracted.write_text(output_text)This code is shorter than the original version, since it inherits its ZIP processing abilities from the parent class. We first import the base class we just wrote and make TextTweaker extend that class. Then, we use super() to initialize the parent class.
We need two extra parameters, and we've used a technique called a fluent interface to provide the two parameters. The find_and_replace() method updates the state of the object, then returns the self object. This lets us use the class with a line of code like the following:
TextTweaker(zip_data)\
.find_and_replace("xyzzy", "plover's egg")\
.process_files("*.md")We've created an instance of the class, used the find_and_replace() method to set some of the attributes, then used the process_files() method to start the processing. This is called a "fluent" interface because a number of methods are used to help clarify the parameters and their relationships.
We've done a fair amount of work to recreate a program that is functionally not different from the one we started with! But having done that work, it is now much easier for us to write other classes that operate on files in a ZIP archive, such as the (hypothetically requested) photo scaler.
Further, if we ever want to improve or bug fix the ZIP functionality, we can do it for all subclasses at once by changing only the one ZipProcessor base class. Therefore maintenance will be much more effective.
See how simple it is now to create a photo scaling class that takes advantage of the ZipProcessor functionality:
from PIL import Image # type: ignore [import]
class ImgTweaker(ZipProcessor):
def transform(self, extracted: Path) -> None:
image = Image.open(extracted)
scaled = image.resize(size=(640, 960))
scaled.save(extracted)Look how simple this class is! All that work we did earlier paid off. All we do is open each file, scale it, and save it back. The ZipProcessor class takes care of the zipping and unzipping without any extra work on our part. This seems to be a huge win.
Creating reusable code isn't easy. It generally requires more than one use case to make it clear what parts are generic and what parts are specific. Because we need concrete examples, it pays to avoid over-engineering to strive for imagined reuse. This is Python and things can be very flexible. Rewrite as needed to cover the cases as they arrive on the scene.
Case study
In this chapter, we'll continue developing elements of the case study. We want to explore some additional features of object-oriented design in Python. The first is what is sometimes called "syntactic sugar," a handy way to write something that offers a simpler way to express something fairly complex. The second is the concept of a manager for providing a context for resource management.
In Chapter 4, Expecting the Unexpected, we built an exception for identifying invalid input data. We used the exception for reporting when the inputs couldn't be used.
Here, we'll start with a class to gather data by reading the file with properly classified training and test data. In this chapter, we'll ignore some of the exception-handling details so we can focus on another aspect of the problem: partitioning samples into testing and training subsets.
Input validation
The TrainingData object is loaded from a source file of samples, named bezdekIris.data. Currently, we don't make a large effort to validate the contents of this file. Rather than confirm the data contains correctly formatted samples with numeric measurements and a proper species name, we simply create Sample instances, and hope nothing goes wrong. A small change to the data could lead to unexpected problems in obscure parts of our application. By validating the input data right away, we can focus on the problems and provide a focused, actionable report back to the user. Something like "Row 42 has an invalid petal_length value of '1b.25'" with the line of data, the column, and the invalid value.
A file with training data is processed in our application via the load() method of TrainingData. Currently, this method requires an iterable sequence of dictionaries; each individual sample is read as a dictionary with the measurements and the classification. The type hint is Iterable[dict[str, str]]. This is one way the csv module works, making it very easy to work with. We'll return to additional details of loading the data in Chapter 8, The Intersection of Object-Oriented and Functional Programming, and Chapter 9, Strings, Serialization, and File Paths.
Thinking about the possibility of alternative formats suggests the TrainingData class should not depend on the dict[str, str] row definition suggested by CSV file processing. While expecting a dictionary of values for each row is simple, it pushes some details into the TrainingData class that may not belong there. Details of the source document's representation have nothing to do with managing a collection of training and test samples; this seems like a place where object-oriented design will help us disentangle the two ideas.
In order to support multiple sources of data, we will need some common rules for validating the input values. We'll need a class like this:
class SampleReader:
"""
See iris.names for attribute ordering in bezdekIris.data file
"""
target_class = Sample
header = [
"sepal_length", "sepal_width",
"petal_length", "petal_width", "class"
]
def __init__(self, source: Path) -> None:
self.source = source
def sample_iter(self) -> Iterator[Sample]:
target_class = self.target_class
with self.source.open() as source_file:
reader = csv.DictReader(source_file, self.header)
for row in reader:
try:
sample = target_class(
sepal_length=float(row["sepal_length"]),
sepal_width=float(row["sepal_width"]),
petal_length=float(row["petal_length"]),
petal_width=float(row["petal_width"]),
)
except ValueError as ex:
raise BadSampleRow(f"Invalid {row!r}") from ex
yield sampleThis builds an instance of the Sample superclass from the input fields read by a CSV DictReader instance. The sample_iter() method uses a series of conversion expressions to translate input data from each column into useful Python objects. In this example, the conversions are simple, and the implementation is a bunch of float() functions to convert CSV string data into Python objects. We can imagine more complex conversions might be present for other problem domains.
The float() functions – when confronted with bad data – will raise a ValueError. While this is helpful, a bug in a distance formula may also raise a ValueError, leading to possible confusion. It's slightly better for our application to produce unique exceptions; this makes it easier to identify a root cause for a problem.
The target type, Sample, is provided as a class-level variable, target_class. This lets us introduce a new subclass of Sample by making one relatively visible change. This isn't required, but a visible dependency like this provides a way to disentangle classes from each other.
We'll follow Chapter 4, Expecting the Unexpected, and define a unique exception definition. This is a better way to help disentangle our application's errors from ordinary bugs in our Python code:
class BadSampleRow(ValueError):
passTo make use of this, we mapped the various float() problems signaled by ValueError exceptions to our application's BadSampleRow exception. This can help someone distinguish between a bad CSV source file and a bad computation due to a bug in a k-NN distance computation. While both can raise ValueError exceptions, the CSV processing exception is wrapped into an application-specific exception to disambiguate the context.
We've done the exception transform by wrapping the creation of an instance of the target class in a try: statement. Any ValueError that's raised here will become a BadSampleRow exception. We've used a raise...from... so that the original exception is preserved to help with the debugging.
Once we have valid input, we have to decide whether the object should be used for training or testing. We'll turn to that problem next.
Input partitioning
The SampleReader class we just introduced uses a variable to identify what kind of objects to create. The target_class variable provides a class to use. Note that we need to be a little careful in the ways we refer to SampleReader.target_class or self.target_class.
A simple expression like self.target_class(sepal_length=, ... etc.) looks like a method evaluation. Except, of course, self.target_class is not a method; it's another class. To make sure Python doesn't assume that self.target_class() refers to a method, we've assigned it to a local variable called target_class. Now we can use target_class(sepal_length=, … etc.) and there's no ambiguity.
This is pleasantly Pythonic. We can create subclasses of this reader to create different kinds of samples from the raw data.
This SampleReader class definition exposes a problem. A single source of raw sample data needs to be partitioned into two separate subclasses of KnownSample; it's either a TrainingSample or a TestingSample. There's a tiny difference in behavior between these two classes. A TestingSample is used to confirm the k-NN algorithm works, and is used to compare an algorithmic classification against the expert Botanist-assigned species. This is not something a TrainingSample needs to do.
Ideally, a single reader would emit a mixture of the two classes. The design so far only allows for instances of a single class to be created. We have two paths forward to provide the needed functionality:
A more sophisticated algorithm for deciding what class to create. The algorithm would likely include an
ifstatement to create an instance of one object or another.A simplified definition of
KnownSample. This single class can handle immutable training samples separately from mutable testing samples that can be classified (and reclassified) any number of times.
Simplification seems to be a good idea. Less complexity means less code and fewer places for bugs to hide. The second alternative suggests we can separate three distinct aspects of a sample:
The "raw" data. This is the core collection of measurements. They are immutable. (We'll address this design variation in Chapter 7, Python Data Structures.)
The Botanist-assigned species. This is available for training or testing data, but not part of an unknown sample. The assigned species, like the measurements, is immutable.
An algorithmically assigned classification. This is applied to the testing and unknown samples. This value can be seen as mutable; each time we classify a sample (or reclassify a test sample), the value changes.
This a profound change to the design created so far. Early in a project, this kind of change can be necessary. Way back in Chapters 1 and 2, we decided to create a fairly sophisticated class hierarchy for various kinds of samples. It's time to revisit that design. This won't be the last time we think through this. The essence of good design is to create and dispose of a number of bad designs first.
The sample class hierarchy
We can rethink our earlier designs from several points of view. One alternative is to separate the essential Sample class from the additional features. It seems like we can identify four additional behaviors for each Sample instance, shown in the following table.
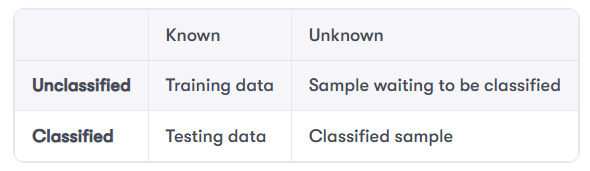
We've omitted a detail from the Classified row. Each time we do a classification, a specific hyperparameter is associated with the resulting classified sample. It would be more accurate to say it's a sample classified by a specific Hyperparameter object. But this might be too much clutter.
The distinction between the two cells in the Unknown column is minute. The distinction is so minor as to be essentially irrelevant to most processing. An Unknown sample will be waiting to be classified for – at most – a few lines of code.
If we rethink this, we may be able to create fewer classes and still reflect the object state and behavior changes correctly.
There can be two subclasses of Sample with a separate Classification object. Here's a diagram.

Figure 5.1: Sample class diagram
We've refined the class hierarchy to reflect two essentially different kinds of samples:
A
KnownSampleinstance can be used for testing or training. The difference between other classes is implemented in the method that does classification. We can make this depend on apurposeattribute, shown with a small square (or sometimes a "-") as a prefix. Python doesn't have private variables, but this marker can be helpful as a design note. The public attributes can be shown with a small circle (or a "+" to save space) as a prefix.When the purpose has a value of
Training, theclassify()method will raise an exception. The sample cannot be re-classified; that would invalidate the training.When the purpose has a value of
Testing, theclassify()method will work normally, applying a givenHyperparameterto compute a species.
An
UnknownSampleinstance can be used for user classification. The classification method here does not depend on the value of thepurposeattribute, and always performs classification.
Let's look at implementing these behaviors with the @property decorator we learned about in this chapter. We can use @property to fetch computed values as if they were simple attributes. We can also use @property to define attributes that cannot be set.
The purpose enumeration
We'll start by enumerating a domain of purpose values:
class Purpose(enum.IntEnum):
Classification = 0
Testing = 1
Training = 2This definition creates a namespace with three objects we can use in our code: Purpose.Classification, Purpose.Testing, and Purpose.Training. For example, we can use if sample.purpose == Purpose.Testing: to identify a testing sample.
We can convert to Purpose objects from input values using Purpose(x) where x is an integer value, 0, 1, or 2. Any other value will raise a ValueError exception. We can convert back to numeric values, also. For example, Purpose.Training.value is 1. This use of numeric codes can fit well with external software that doesn't deal well with an enumeration of Python objects.
We'll decompose the KnownSample subclass of the Sample class into two parts. Here's the first part. We initialize a sample with the data required by the Sample.__init__() method plus two additional values, the purpose numeric code, and the assigned species:
class KnownSample(Sample):
def __init__(
self,
sepal_length: float,
sepal_width: float,
petal_length: float,
petal_width: float,
purpose: int,
species: str,
) -> None:
purpose_enum = Purpose(purpose)
if purpose_enum not in {Purpose.Training, Purpose.Testing}:
raise ValueError(
f"Invalid purpose: {purpose!r}: {purpose_enum}"
)
super().__init__(
sepal_length=sepal_length,
sepal_width=sepal_width,
petal_length=petal_length,
petal_width=petal_width,
)
self.purpose = purpose_enum
self.species = species
self._classification: Optional[str] = None
def matches(self) -> bool:
return self.species == self.classificationWe validate the purpose parameter's value to be sure it decodes to either Purpose.Training or Purpose.Testing. If the purpose value isn't one of the two allowed values, we'll raise a ValueError exception because the data is unusable.
We've created an instance variable, self._classification, with a leading _ name. This is a convention that suggests the name is not for general use by clients of this class. It's not "private," since there's no notion of privacy in Python. We could call it "concealed" or perhaps "watch out for surprises here."
Instead of a large, opaque wall available in some languages, Python uses a low, decorative floral border that sets this variable apart from the others. You can march right through the floral _ character to look at the value closely, but you probably shouldn't.
Here's the first @property method:
@property
def classification(self) -> Optional[str]:
if self.purpose == Purpose.Testing:
return self._classification
else:
raise AttributeError(f"Training samples have no classification")This defines a method that will be visible as an attribute name. Here's an example of creating a sample for testing purposes:
>>> from model import KnownSample, Purpose
>>> s2 = KnownSample(
... sepal_length=5.1,
... sepal_width=3.5,
... petal_length=1.4,
... petal_width=0.2,
... species="Iris-setosa",
... purpose=Purpose.Testing.value)
>>> s2
KnownSample(sepal_length=5.1, sepal_width=3.5, petal_length=1.4, petal_width=0.2, purpose=1, species='Iris-setosa')
>>> s2.classification is None
TrueWhen we evaluate s2.classification, this will call the method. This function makes sure this is a sample to be used for testing, and returns the value of the "concealed" instance variable self._classification.
If this is a Purpose.Training sample, the property will raise an AttributeError exception because any application that checks the value of the classification for a training sample has a bug in it that needs to be fixed.
Property setters
How do we set the classification? Do we really execute the statement self._classification= h.classify(self)? The answer is no – we can create a property that updates the "concealed" instance variable. This is a bit more complex than the example above:
@classification.setter
def classification(self, value: str) -> None:
if self.purpose == Purpose.Testing:
self._classification = value
else:
raise AttributeError(
f"Training samples cannot be classified")The initial @property definition for classification is called a "getter." It gets the value of an attribute. (The implementation uses the __get__() method of a descriptor object that was created for us.) The @property definition for classification also creates an additional decorator, @classification.setter. The method decorated by the setter is used by assignment statements.
Note that the method names for these two properties are both classification. This is the attribute name to be used.
Now a statement like s2.classification = h.classify(self) will change the classification from a particular Hyperparameter object. This assignment statement will use the method to examine the purpose of this sample. If the purpose is testing, the value will be saved. If the purpose is not Purpose.Testing, then attempting to set a classification raises an AttributeError exception, and identifies a place where something's wrong in our application.
Repeated if statements
We have a number of if statements checking for specific Purpose values. This is a suggestion that this design is not optimal. The variant behavior is not encapsulated in a single class; instead, multiple behaviors are combined into a class.
The presence of a Purpose enumeration and if statements to check for the enumerated values is a suggestion that we have multiple classes. The "simplification" here isn't desirable.
In the Input partitioning section of this case study, we suggested there were two paths forward. One was to try and simplify the classes by setting the purpose attribute to separate testing from training data. This seems to have added if statements, without really simplifying the design.
This means we'll have to search for a better partitioning algorithm in a later chapter's case study. For now, we have the capability of creating valid data, but we also have code that's cluttered with if statements. The reader is encouraged to try alternative designs to examine the resulting code to see what seems simpler and easier to read.
Recall
Here are some of the key points in this chapter:
When we have both data and behavior, this is the sweet spot for object-oriented design. We can leverage Python's generic collections and ordinary functions for many things. When it becomes complex enough that we need to be sure that pieces are all defined together, then we need to start using classes.
When an attribute value is a reference to another object, the Pythonic approach is to allow direct access to the attribute; we don't write elaborate setter and getter functions. When an attribute value is computed, we have two choices: we can compute it eagerly or lazily. A property lets us be lazy and do the computation just in time.
We'll often have cooperating objects; the behavior of the application emerges from the cooperation. This can often lead to manager objects that combine behaviors from component class definitions to create an integrated, working whole.
Exercises
We've looked at various ways that objects, data, and methods can interact with each other in an object-oriented Python program. As usual, your first thoughts should be how you can apply these principles to your own work. Do you have any messy scripts lying around that could be rewritten using an object-oriented manager? Look through some of your old code and look for methods that are not actions. If the name isn't a verb, try rewriting it as a property.
Think about code you've written in any language. Does it break the DRY principle? Is there any duplicate code? Did you copy and paste code? Did you write two versions of similar pieces of code because you didn't feel like understanding the original code? Go back over some of your recent code now and see whether you can refactor the duplicate code using inheritance or composition. Try to pick a project you're still interested in maintaining, not code so old that you never want to touch it again. That will help to keep you interested when you do the improvements!
Now, look back over some of the examples we looked at in this chapter. Start with the cached web page example that uses a property to cache the retrieved data. An obvious problem with this example is that the cache is never refreshed. Add a timeout to the property's getter, and only return the cached page if the page has been requested before the timeout has expired. You can use the time module (time.time() - an_old_time returns the number of seconds that have elapsed since an_old_time) to determine whether the cache has expired.
Also look at the inheritance-based ZipProcessor. It might be reasonable to use composition instead of inheritance here. Instead of extending the class in the ZipReplace and ScaleZip classes, you could pass instances of those classes into the ZipProcessor constructor and call them to do the processing part. Implement this.
Which version do you find easier to use? Which is more elegant? What is easier to read? These are subjective questions; the answer varies for each of us. Knowing the answer, however, is important. If you find you prefer inheritance over composition, you need to pay attention that you don't overuse inheritance in your daily coding. If you prefer composition, make sure you don't miss opportunities to create an elegant inheritance-based solution.
Finally, add some error handlers to the various classes we created in the case study. How should one bad sample be handled? Should the model be inoperable? Or should the row be skipped? There are profound data science and statistical consequences to a seemingly small technical implementation choice. Can we define a class that permits either alternative behavior?
In your daily coding, pay attention to the copy and paste commands. Every time you use them in your editor, consider whether it would be a good idea to improve your program's organization so that you only have one version of the code you are about to copy.
Summary
In this chapter, we focused on identifying objects, especially objects that are not immediately apparent; objects that manage and control. Objects should have both data and behaviors, but properties can be used to blur the distinction between the two. The DRY principle is an important indicator of code quality, and inheritance and composition can be applied to reduce code duplication.
In the next chapter, we'll look at Python's methods for defining abstract base classes. This lets us define a class that's a kind of template; it must be extended with subclasses that add narrowly-defined implementation features. This lets us build families of related classes, confident that they will work together properly.
About the Author:
Steven Lott has been programming since computers were large, expensive, and rare. Working for decades in high tech has given him exposure to a lot of ideas and techniques, some bad, but most are helpful to others. Since the 1990s, Steven has been engaged with Python, crafting an array of indispensable tools and applications. His profound expertise has led him to contribute significantly to Packt Publishing, penning notable titles like Mastering Object-Oriented Python (Packt, 2019), Modern Python Cookbook (Packt, 2024), and Python Real-World Projects (Packt, 2023). A self-proclaimed technomad, Steven's unconventional lifestyle sees him residing on a boat, often anchored along the vibrant east coast of the US. He tries to live by the words “Don’t come home until you have a story.”
Lott is currently working on the 5th Ed. of Python Object-Oriented Programming due later this year. If you liked this chapter and want more right now, you can check out Python Object-Oriented Programming, 4th Ed. (Packt, 2021).

Here is what some readers have said:


