



TableGen – LLVM Swiss Army Knife for Modeling
The complete “Chapter 6: TableGen – LLVM Swiss Army Knife for Modeling” from the book LLVM Code Generation by Quentin Colombet (Packt, May 2025).

For every target, there are a lot of things to model in a compiler infrastructure to be able to do the following:
Represent all the available resources
Extract all the possible performance
Manipulate the actual instructions
This list is not exhaustive, but the point IS that you need to model a lot of details of a target in a compiler infrastructure.
While it is possible to implement everything with your regular programming language, such as C++, you can find more productive ways to do so. In the LLVM infrastructure, this takes the form of a domain-specific language (DSL) called TableGen.
In this chapter, you will learn the TableGen syntax and how to work your way through the errors reported by the TableGen tooling. These skills will help you be more productive when working with this part of the LLVM ecosystem.
This chapter focuses on TableGen itself, not the uses of its output through the LLVM infrastructure. How the TableGen output is used is, as you will discover, TableGen-backend-specific and will be covered in the relevant chapters. Here, we will use one TableGen backend to get you accustomed to the structure of the TableGen output, starting you off on the right foot for the upcoming chapters.
Before getting started with TableGen, let’s briefly discuss the technical requirements.
Technical requirements
In this chapter, you will wrestle directly with the TableGen tooling that comes with the LLVM releases. At this point, you know the drill concerning the tools that you need to build a project using the LLVM infrastructure (Git, CMake, Ninja, and the C++ toolchain).
Additionally, you will find the code for the examples in this chapter in a folder named ch6, which can be found in the GitHub repository of this book: https://github.com/PacktPublishing/LLVM-Code-Generation.
Without further ado, let’s start our journey with TableGen.
Getting started with TableGen
The name TableGen stems from its original usage – generating tables. For instance, TableGen generates the table that represents all the registers of a target. TableGen outgrew this purpose and is now used to model a wide range of things, from Clang’s command-line options to multi-level intermediate representation (MLIR) operations’ boilerplate C++ code, or used directly within LLVM to generate the instruction selection tables, and so on.
Fundamentally, TableGen is a DSL to produce records. A record is an entity with a name and an arbitrary number of fields, where each field has its own type.
How these records are used and what output TableGen generates from them depends on the specific TableGen backend.
We will survey one of the TableGen backends used in this book in the Discovering a TableGen backend section, but you will learn how to use this backend and the other ones in the relevant upcoming chapters.
TableGen’s strength lies in how you can structure the generation of your records such that you can factor out the repeated parts of records.
For instance, imagine that you want to produce records that hold the ages and names of people. Without even describing the TableGen syntax yet, this could look like the following snippet:
class Person<int age, string name> {
int _age = age;
string _name = name;
}
def A: Person<23, "A">;
def B: Person<64, "B">;
def /*Anonym*/: Person<43, "anonymous">;Note how the boilerplate of our records is gathered in just one location, the Person class, and how easy it is to create a record for each person (A, B, etc.).
Then, you can process that input (saved in a file named person.td, in this case) through TableGen with the following command:
$ ${LLVM_INSTALL_DIR}/bin/llvm-tblgen person.tdRunning this command will yield the following records:
def A { // Person
int _age = 23;
string _name = "A";
}
def B { // Person
int _age = 64;
string _name = "B";
}
def anonymous_0 { // Person
int _age = 43;
string _name = "anonymous";
}As you can see, TableGen’s basic functionality expands a structured representation of your records into a mostly flat representation. The parts that do not get flattened are the fields with non-built-in types.
To summarize, TableGen is a sort of glorified string concatenation tool, at least for the frontend part.
The interesting bits happen when you enable a TableGen backend (through one of the --gen-xxx options of the llvm-tblgen tool). When a TableGen backend is enabled, TableGen feeds the records, after flattening them all, to the related backend. The backend then generates what is expected from these records, and this content is included in the related part of the LLVM infrastructure. Where and how things are included depends on the usage of the generated information, but the general mechanism remains the same for all of them, as illustrated in Figure 6.1.

Figure 6.1: Usage of TableGen in LLVM
In Figure 6.1, an input file, usually with the .td suffix, which stands for target description, is fed to TableGen. The TableGen frontend generates flattened records and feds them to the desired backend. The backend generates its output in a file with a .inc suffix. That suffix indicates that this file needs to be included somewhere else to make sense. The type of output in the .inc file depends on the backend, but usually in LLVM, TableGen is used to produce C++ code.
The invocation of TableGen happens at build time. The content of certain LLVM files depends on the presence of the .inc files, and they are generated as part of the build process. This is why building TableGen in release mode, as described in , can help you speed up your build time even if you are interested in building your whole compiler in debug mode.
Note
Even if you are tempted to modify the content of a
.incfile, do not! Although this is fine for exploration purposes, the.incsuffix is used as an indication that the related file has been automatically generated. In other words, if you want to modify it, you must modify its source; hence, find its related.tdfile.
In this section, you learned the basic mechanics of TableGen. You saw that it is used as a DSL to generate, at build time, information included by the rest of the LLVM infrastructure. You also learned that what is generated is TableGen-backend specific.
Before looking at the TableGen backends more closely, let’s get a primer on the TableGen syntax.
The TableGen programming language
In this section, we will offer a primer on the TableGen syntax. The goal here is not for you to become a TableGen programmer but to know enough so that you can understand what you read and write when working with TableGen in the rest of this book. For a more thorough explanation of the TableGen syntax, consult the Further reading section.
As you saw in the previous section, TableGen is a language used to generate records. It relies on two main constructs to describe its records:
class: A way to structure, pre-fill, and specify a type for recordsdef: An instantiation of a record
The general syntax to describe a record is as follows:
def [optionalName][: optionalClassA[<argN[, argM]*>][, optionalClassB[<argV[, argW]*>]]*] [{
[type fieldName [ = value];]*
}];In this snippet, everything between [ and ] is optional, and the * character means, as usual for regular expression, that the previous expression is repeated zero or more times.
Additionally, argX are the potentially required arguments of the related class. They must match in type and number at least all the non-default arguments specified for this class (see the Types section for more details). Then, value is used to initialize fieldName, and it must have the same type as type. The syntax of value depends on type.
Note
When you use other records in your fields (e.g., when
valueis another record), TableGen creates a reference to the original record. In other words, records are never copied.
A record instantiated with optionalClassX inherits all the fields of the respective class or classes. You can assign as many classes as you want to a record, as shown in the following snippet:
def MyRecord: classA, classB;The resulting record will have the following traits:
Be usable as an instance of each of these classes (for example,
MyRecordcan be used in bothlist<classA>andlist<classB>instances).Be the union of all the fields of all the classes.
Note
If two classes have a field with the same name and are used together to instantiate a record, only the last seen field is kept. Similarly, if a record declares a field of the same name, only this one is kept. In other words, unlike C++ inheritance, name collisions cannot be disambiguated, and the last instantiated one wins.
Note that a record does not need to be typed. In other words, a record can be instantiated with just a def statement.
Let’s now focus on the available types in TableGen, the topic of our next section.
Types
While a record may not be typed, every field in a record must be typed. The types can be either one of the built-in types or user-defined.
The built-in types are as follows:
int: A 64-bit integer valuebit: A zero or onebits<size>: A sequence ofsizeof zeros and onesstring: A sequence of arbitrary characterslist<type>: A sequence oftypeelementsdag: A structure that represents a directed acyclic graph (DAG). Without going into details, you can view this as arbitrary nested lists where each list starts with an operator (e.g.,(add (mul a, b), (div c, d))is the DAG that represents a math expression of the form(a * b) + (c / d)). This is useful, for instance, to describe instruction selection patterns.
To initialize the integer-like types (int, bit, and bits) you can use your preferred C-style syntax for decimal and hexadecimal numbers, or the TableGen binary format in the 0b form, followed by zeros and ones.
For strings, simply use the C-style string syntax.
On top of the built-in types, you can create your own types using the class keyword. A class offers a convenient way to structure your records and can be parametrized with optional arguments, using a syntax close to C++ templates.
Using the same convention as the definition of a record, the definition of a class resembles the following:
class ClassName[<type arg1[, type arg2]*>] [: superclass1[<argN[, argM]*>] [, superclass2[<argV[, argW]*>]]*] [{
[type fieldName [ = value];]*
}];The class’s arguments can be set to a default value and used in the body of the class.
For instance, we can modify our Person class from earlier to set a default name:
class Person<int age, string name = "anonymous"> {
int _age = age;
string _name = name;
}With this snippet, the instantiation of a record of type Person does not need to set the name argument anymore. Instead, "anonymous" will be automatically filled in.
This concludes the primer on types in TableGen.
Next, let’s introduce some of the programming capabilities that TableGen offers.
Programming with TableGen
TableGen offers some basic programmability features to make the description of your records more compact. These are called bang operators, and they are all prefixed with the ! character (i.e., the bang operator in C, hence the name) – for example, !add and !range.
For instance, you can define a record with a list of integers from 0 to 10 without the number 5, and then count how many items there are in the list by using something like the following:
def MyRecord {
list<int> ZeroTo10No5 =
!filter(var, !range(0, 10), !ne(var, 5));
int num = !size(ZeroTo10No5);
}In this snippet, we define a list of integers from 0 to 10 by using the !range operator. We then give this list of integers to the !filter operator. This operator iterates through this list and checks whether the current element, stored in the variable named var (defined by the first argument of the operator), matches the predicate given as its third argument – in this case, the !ne operator. !ne checks that two values are not equal.
Note how you can reference other fields (here ZeroTo10No5) when defining another one (here, num).
You can find the complete list of the bang operators at https://llvm.org/docs/TableGen/ProgRef.html#bang-operators.
Before we finish with the TableGen syntax, there is one last important concept that you need to be aware of – multi-class. Let’s cover this topic in our next section.
Defining multiple records at once
With its obsession with compact code, TableGen offers a way to create a template for multiple records at once. You can use it with the multiclass keyword for the description of the template and the defm keyword for the instantiation of the records.
Before we dive into the syntax of these constructs, we want to highlight that, unlike classes, multi-classes are not types per se. You can instantiate a (multi-)record with a multi-class, but you cannot use a multi-class as the type parameter of list, for instance. We will illustrate this difference with an example, but first, let’s lay down the syntax.
Using the same convention as before, here is what a multi-class definition looks like:
multiclass name[<type [arg1, type arg2]*>][: optionalMulticlassA[<argN[, argM]*>][, optionalMulticlassB[<argG[, argH]*>]]* [{
[def|defm recordSuffix // full record definition]*
}]In this snippet, you can see that you can only describe multi-classes through other multi-classes (i.e., the initialization list accepts only multi-classes), but you can put as many (multi-)records as you want in its body.
While the (multi-)record’s definition in the multi-class body is the full record’s body (i.e., it follows the syntax shown earlier), the record is not instantiated just yet. Instead, the records described in a multi-class are instantiated when a standalone defm statement is used.
Using the same convention as before, a defm statement looks like the following expression:
defm [optionalName] : multiclassA[<argN[, argM]*>][, multiclassB[<argV[, argW]*>]]*[,classD[<argY[, argZ]*>]]*;A defm statement instantiates multiple records at once. All the records from all the multiclassX templates are instantiated, and their names are, by default, prepended by optionalName. In other words, by using this snippet and the previous multi-class one, the resulting record’s name will be optionalName followed by recordSuffix. Additionally, each record is augmented with the fields found in the union of all of classX.
Note
If you do not set a name for your record (in other words, if you leave a blank between the
defordefmkeyword and the body of the (multi-)record), TableGen will automatically assign a unique name to your record(s). You have actually already experienced that, in the very first example, wheredef /*Anonym*/: ...produced the record nameddef anonymous_0!
To make the multiclass and defm constructs more concrete, let’s look at an example that uses them.
Consider the following snippet:
multiclass Bundle<string base> {
def A {
string name = !strconcat(base, "-", "A");
int price = 12;
int weight = 1;
}
def B {
string name = !strconcat(base, "-", "B");
string tag = "special";
}
}
class ShippingPrice<int arg> {
int shippingPrice = arg;
}
defm valuedBundle : Bundle<"valued">, ShippingPrice<5>;In this snippet, we declare one multi-class (Bundle) and one class (ShippingPrice). The multi-class defines two records, A and B. When we instantiate this multi-class with valuedBundle, we immediately create two records, named valuedBundleA and valuedBundleB (i.e., the name given to the defm statement, prepended to the two definitions from within the multi-class). Moreover, these records end up with a shippingPrice field with a value of 5, due to the usage of ShippingPrice<5> at the end of the defm statement.
Note that you can see which records are generated for this example by following the README.md instructions in the ch6 file for the multiclass.td example.
Now that you have a better grasp of what a multi-class is, you can understand why this is not the kind of type that can appear in a list definition. To clarify this, as you saw, a multi-class is a collection of records, not a type per se. Each of these records may have distinct types, and they are technically never held together.
In other words, the following snippet is invalid:
list<Bundle> // errorHowever, let’s say we add a definition of type Gift under the name C in our Bundle multi-class. After the defm statement of our previous example, a valuedBundleC record exists and has the Gift type (defined earlier as a class). Now, this record can be used in a list of Gift:
def AnotherRecord {
list<Gift> gifts = [valuedBundleC];
}We are almost done with our survey of the TableGen programming language; we are missing just one thing relating to field assignment that is used a lot in the LLVM code base. Let’s address that in the next section.
Assigning fields
TableGen offers diverse ways to assign a value to a field. Some ways take precedence over others, and since they are all used extensively in the LLVM code base, it is important you know about them.
You already know two of them:
Assignment via multi-class/class arguments
Plain assignment (e.g., with a literal/argument)
There is a third way that you need to know; it uses the let keyword with or without the in keyword.
The let keyword allows to override the values of a list of fields for the specified context. Without the in keyword, the context is the current record or class.
When used in a record or class, the syntax of a let statement is as follows:
let fieldName1 = newVal1[, fieldName2 = newVal2]*;When using a let keyword in a record or class, all fieldNameX instances must have been previously defined. The let keyword assigns newValX to fieldNameX.
Now, if you want to define a context for the effect of let, you use the following construct:
let FieldName1 = NewVal1[, FieldName2 = NewVal2]* inCompared to the version without the in keyword, field names will be resolved in the context of the statement right after in. This means that fieldNameX can reference field names that are yet to be defined. Additionally, the statement right after the in keyword can be arbitrarily large by encompassing it with { and } characters.
This means you can override the values of many fields for many records at once.
Finally, let’s define the order of evaluation of the ways of assigning a value. Since the let keyword is used for overriding, it is evaluated after the regular field assignments (i.e., any non-let assignments are resolved first). Now, if there are several let-statements that affect the same field in the same context, the last one, in a file order from top to bottom, wins.
To make this clearer, consider the following example:
class MyClass<string _alias=""> {
string alias = _alias;
}
let alias = "let from out" in
def A: MyClass<> {}
def B: MyClass<> {
let alias = "let from body";
}
def C: MyClass<"from arg">;
let alias = "alias from bigger scope" in {
let alias = "let from out" in
def D: MyClass<"from arg"> {
let alias = "let from body";
}
def E: MyClass<"will be overridden">;
} // end "alias from bigger scope"In this example, you see the different assignment mechanisms in action on the field named alias:
For record
A,aliasis overridden with alet-statement right after the definition of the record.aliaswill have the"let from out"value.For record
B,aliasis overridden within the body of the record. It will have the"let from body"value.For record
C, we use a regular assignment (alias = _aliasfrom withinMyClass) after passing the value we want,"from arg", as a class argument.For record
D, focus on theletstatements, since they override everything else. Then, find the last one –aliaswill have the"let from body"value.Record
Elooks innocent at first, but note that we are still within the context of theletstatement that started slightly before recordD. As such, the value ofaliaswill have the value of thisletstatement (i.e.,"alias from bigger scope").
This concludes the basic skills you need to navigate the .td files in the LLVM code base. You will see that TableGen offers some other constructs that you should be already familiar with, such as comments (// and /* */) and includes (include "path"), but you should already be familiar with these concepts.
Note
In TableGen, there is no concept of header files. As such, you will not find any guard construct (the
ifndef/defineconstruct in the C-world), and includes flow transitively in the included files. This means two things. First, if you include a file twice, even transitively (e.g., ifAincludesBandC, andBincludesD, andCalso includesD, it implies thatAincludesDtwice (once throughBand once throughC)), you will end up with a lot of errors around redefined records/classes. If that happens, double-check your includes in the global context. Second, it is okay to assume that a bigger context includes what you need in your.tdfile and materialize the dependencies accordingly (e.g., for the previous example, you would haveAincludesB,CandD,Bincludes nothing, andCincludes nothing;Dneeds to be included beforeBandCinA).
In this section, you learned how to read, write, and understand TableGen files. You got accustomed to the not-so-intuitive multiclass and defm constructs, and you saw how to leverage let statements to modify your records after the fact.
The next section will prime you on the usage of TableGen in the LLVM infrastructure by presenting a TableGen backend used in LLVM.
Discovering a TableGen backend
Although we could have fun creating records all day long, there is not much point to it if we don’t do anything with them. Therefore, in this section, you will discover one of the TableGen backends used to build LLVM – in other words, how records that you create are consumed and used in LLVM.
While the content of this section remains high-level, we believe understanding the purpose of the records that you will build makes you more effective at it. First, it will help you build a mental model of the inner workings of TableGen, and second, it will give you confidence in approaching new TableGen backends.
Let’s start this section with some information that applies to all the TableGen backends that target LLVM.
General information on TableGen backends for LLVM
If you are building several projects within the LLVM umbrella, you will see that different projects use different TableGen drivers. For instance, while LLVM proper has llvm-tblgen, Clang has clang-tblgen, and MLIR has mlir-tblgen.
The main difference between these drivers is the TableGen backends they offer. Otherwise, the frontend is the same for all of them, meaning that what you learned on the TableGen syntax applies to all of them as well.
In this book, you will interact solely with the llvm-tblgen tool (i.e., the driver of the LLVM project).
Using this tool, you can see all the available backends by running the following on the command line:
$ llvm-tblgen --helpThis will print a list of all the command-line options supported by the tool and the --gen-xxx options that, by convention, represent the available backends.
From that point, you can start playing with the different backends.
Now, more realistically, you do not want to start playing with a specific backend from scratch. Indeed, you need to provide certain records for the backends to do what they are meant to do. (You will learn what these records are in the relevant upcoming chapters.) Moreover, these records rely on classes that are provided by the core LLVM infrastructure, and you do not want to rediscover where these live and so on. Put differently, you do not want to rediscover the build dependencies manually. Instead, you want to leverage the build system to provide you with the right command for a specific backend.
If you are dealing with an issue with TableGen, chances are your build system will fail while building the related .inc file, so you will get this command line easily. If not, you can rebuild this .inc file with the right build target, as explained in the A Crash course on Ninja section in .
For instance, here is the command line reported by the build system for the lib/Target/AArch64/AArch64GenInstrInfo.inc target (i.e., the instr-info backend when run for the AArch64 backend):
$ llvm-tblgen -gen-instr-info -I ${LLVM_SRC}/llvm/lib/Target/AArch64 -I${LLVM_BUILD}/include -I ${LLVM_SRC}/llvm/include -I ${LLVM_SRC}/llvm/lib/Target ${LLVM_SRC}/llvm/lib/Target/AArch64/AArch64.td --write-if-changed -o lib/Target/AArch64/AArch64GenInstrInfo.inc -d lib/Target/AArch64/AArch64GenInstrInfo.inc.dIrrespective of how you get your llvm-tblgen command line, the point is that this is your starting point for further exploration or debugging.
For existing LLVM backends, you can further check how a .inc file fits in the overall picture by looking at how it’s used.
For instance, the following command line, run at the root of ${LLVM_SRC}, gives all the files that directly use AArch64GenInstrInfo.inc:
$ git grep -l 'AArch64GenInstrInfo\.inc"' -- llvmNow, you know how to discover what backends exist and how to find the proper command-line invocation for them.
The next section takes you a little bit deeper into the world of a TableGen backend.
Discovering a TableGen backend
Sadly, most TableGen backends are under-documented. The good news is that all of them are used by at least one open source target. Using this open source target, you can see what the related .inc file looks like, and you can forge a mental model of how the related .td files connect to this output.
This section presents what one TableGen backend generates. This information will help you build some reflexes of how to approach TableGen backends that you have never worked with. By seeing how a backend works, you will learn what to look for when approaching a new backend.
We focused on one of the backends you will use later in this book, but we did not document all the ones that you will use. However, you can use the same approach to reverse-engineer how all the TableGen backends work.
Let’s now focus on the TableGen backend used to generate the information for the intrinsics.
The implementation of intrinsics
At the LLVM intermediate representation (IR) level, intrinsics are special functions known by the compiler. They usually map to specific target instructions. For instance, the LLVM function named llvm.aarch64.ldxr is an intrinsic at the LLVM IR level that maps to the LDXRB instruction of the AArch64 backend.
The TableGen backend that we cover here generates the LLVM IR boilerplate to use this intrinsic. The mapping to the final instruction is outside of the scope of this backend. You can invoke this backend through the llvm-tblgen executable by using the -gen-intrinsic-impl option.
You can look at the generated boilerplate by opening ${LLVM_BUILD}/include/llvm/IR/IntrinsicImpl.inc.
Let’s look at the content of this file.
The content of a generated file
Looking into IntrinsicImpl.inc, the interesting bits are how the generated code is structured. The file is virtually split into several sections. Each section is guarded by a macro, #ifdef GET_[LLVM_]INTRINSIC_XXX, where XXX is, in this case, one of IITINFO, TARGET_DATA, NAME_TABLE, and so on. Each section has its own usage ,as described in Table 6.1:
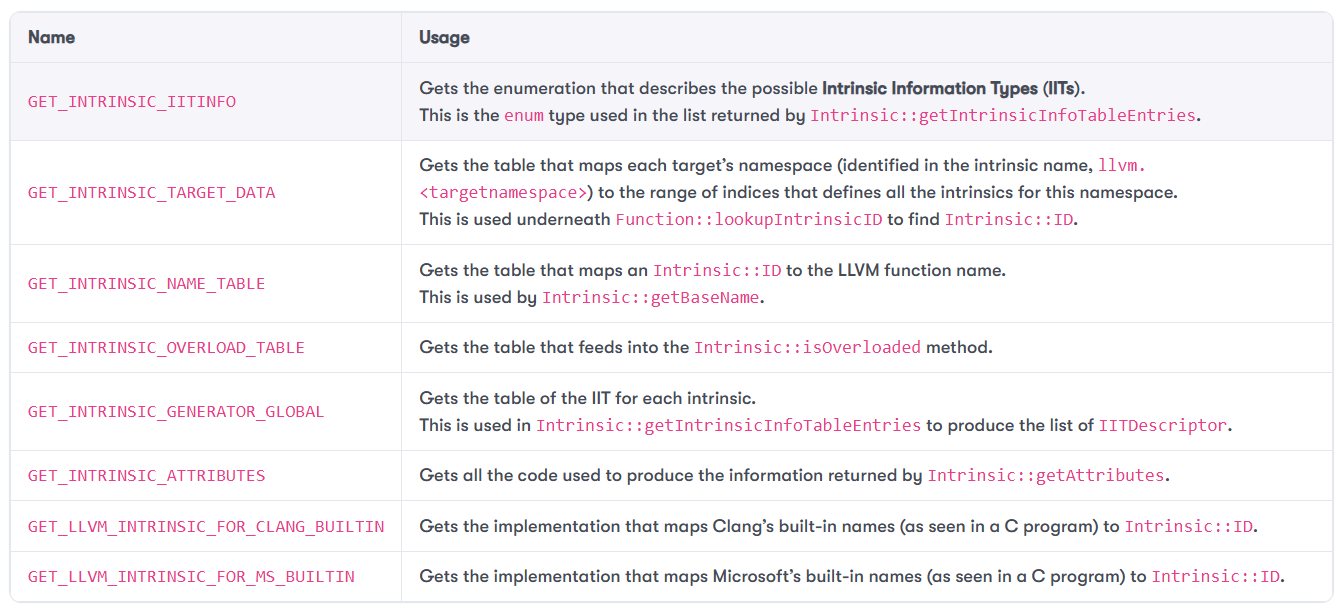
Table 6.1: Macros that guard the generated output of the IntrinsicImpl TableGen backend
If you look at the other TableGen backends used by LLVM, you will see the same structure – virtual sections enabled by different macros and included in various parts of the LLVM infrastructure.
For this TableGen backend, you can find these usages by looking at how IntrinsicImpl.inc is included throughout the LLVM code base.
Let’s now look at what drives this backend.
The source of a TableGen backend
The main source file used by the IntrinsicImpl TableGen backend in the LLVM build system is ${LLVM_SRC}/llvm/include/llvm/IR/Intrinsics.td.
This file contains the classes and records that are used to define all the target-specific intrinsics.
The thing that may be difficult to untangle with TableGen is that the backend draws some information from specific classes and/or records. In other words, records can be more than just an instantiation of a class.
For instance, consider the following snippet from Intrinsics.td:
def IntrArgMemOnly : IntrinsicProperty;
def IntrInaccessibleMemOnly : IntrinsicProperty;These two records have the same type (IntrinsicProperty) and carry the same field values. Therefore, you might think that they are interchangeable, but this is not true!
The name of certain records carries special significance for the related backend.
In this case, the IntrinsicEmitter class (located in llvm/utils/TableGen), which implements this TableGen backend, uses these records to classify the memory effects of the intrinsics and generates different C++ code based on that.
For instance, you can see from the following snippet from IntrinsicsAArch64.td how IntrArgMemOnly can be used to define a particular intrinsic:
def int_aarch64_settag : DefaultAttrsIntrinsic<[], [llvm_ptr_ty, llvm_i64_ty], [IntrWriteMem, IntrArgMemOnly, NoCapture<ArgIndex<0>>, WriteOnly<ArgIndex<0>>]>;The takeaway is that by only looking at a .td file, it is impossible to determine what are considered built-in constructs for a specific backend and what are just the uses of these constructs!
To remediate that problem, the authoring of TableGen files in LLVM is structured such that important records and classes are in one main include file (here Intrinsics.td) and the instantiation of these concepts is in target-specific files (here IntrinsicsXXX.td where XXX is the name of the related backend.) What this means is the classes and records that you may find in IntrinsicsXXX.td are specific to these files and are not load-bearing for the TableGen backend itself. In other words, you can interpret them as regular records and classes (i.e., a way to share information between records). The records and classes defined in the generic files usually hold a lot of comments that will help you instantiate your own records.
What you saw in this section applies to all TableGen backends in LLVM. For instance, if you look at ${LLVM_BUILD}/lib/Target/AArch64/AArch64GenGlobalISel.inc, which is the output of the GlobalISel selector (-gen-global-isel) TableGen backend, you will find the guarded sections (e.g., GET_GLOBALISEL_PREDICATE_BITSET and GET_GLOBALISEL_TEMPORARIES_DECL), the load-bearing records and classes (in ${LLVM_SRC}/llvm/include/llvm/Target/Target.td), and the LLVM-backend-specific implementation (in ${LLVM_SRC}/llvm/lib/Target/AArch64/AArch64.td).
In this section, you learned that, sadly, the best way to approach a TableGen backend is to look at what was implemented in another LLVM backend. However, by discovering the general principles behind each TableGen backend used in LLVM, you learned how to follow basic threads to forge an understanding of the main classes and records leveraged by the related backends.
The next section covers tips and tricks to help you troubleshoot issues with a TableGen backend.
Debugging the TableGen framework
When you interact with TableGen, it may not be immediately obvious what part of TableGen fails you, or how you misused it!
In this section, you will learn ways to determine what goes wrong. The way to fix the problem may, however, be backend-specific, and given the sheer volume of TableGen backends, we will not cover this in this book. However, we give you general guidance on how to approach them.
Let’s start with the basics!
Identifying the failing component
As you learned in Getting started with TableGen, a TableGen workflow implies several components – the frontend, the backend, and the use of the generated output in LLVM.
To identify which component is at fault, you need to identify when the failure occurs:
If the failure occurs while producing the
.incfile, the problem is either with the TableGen frontend or backend, the syntax you used, or how you used the specific constructs (class or record) of this backend.If the failure occurs while building a part of LLVM that includes the
.incfile, the problem is with the TableGen backend, how you used the specific constructs of this backend, or the code that uses that generated file.If the failure occurs while running the compiler, the problem is with the TableGen backend, the code that uses it, or how you used the specific constructs of this backend.
Most of the TableGen backends have been around for a while and used quite a lot. Therefore, if something breaks at build time but after the .inc file has been generated (case 2) or at runtime (case 3), chances are the issue is in how you described your records. If you cannot find the issue yourself or believe there is a bug in the related TableGen backend, engage with the LLVM community. You may, for instance, help future developers by making the related TableGen backend produce a warning for the problematic case, instead of generating something dubious!
This leaves us with case 1 – TableGen failing to generate the .inc file.
At this point, TableGen should report an error. Your job is to find out whether this error comes from the TableGen frontend or backend.
To easily identify whether you are dealing with a frontend or a backend error, do the following:
Find the command line that generates the
.incfile (refer back to the General information on TableGen backends for LLVM section).Remove the
-gen-xxxoptions.Add the
-print-recordsoption.Run the resulting command.
If the error remains, you are dealing with a TableGen frontend error. In other words, your syntax is incorrect. Usually, the frontend errors come with a line and column number referencing the input file.
If the error disappears, you are dealing with a backend-specific error, which we will discuss in the next section.
Cracking open a TableGen backend
Most of the time, the error reported by a TableGen backend gives you enough information to infer what you need to do to solve it.
For instance, imagine you want to use the GlobalISel selector backend and you get the following error:
error: The class 'HwMode' is not definedThis is straightforward – you miss a record of the HwMode class in your .td file for the backend to be able to operate.
To find this class, you can leverage git grep (see the following code snippet), or you can follow the include directory (-I option) to find the .td file where the important classes and records are defined (in this case, ${LLVM_SRC}/llvm/include/llvm/Target/Target.td):
$ cd ${LLVM_SRC}; git grep 'class HwMode' -- llvm/include/llvm | grep '\.td'The previous command goes into the ${LLVM_SRC} directory, looks for the definition of the HwMode class, and filters the result such that only .td files are printed.
Then, later, let’s say the next error is as follows:
input.td:13:1: error: Record `anonymous_7223', field `InstructionSet' does not have a def initializer!This time, this is a frontend error that tells us that the InstructionSet field is not initialized. In other words, this means we did not set a value for that field but we should have. (There is no default initializer in this case.) We just need to check what the type of InstructionSet is to see how to instantiate a record appropriately and move on.
After all that, if you still encounter errors that may not have an obvious fix and the community cannot help you, this is where the fun starts!
If you are lucky, the backend features a rich enough debug log for you to understand what is going on. To enable it, add -debug to the llvm-tblgen command line.
If this is not enough, you must dig into the C++ code of the related backend. All the backends live under ${LLVM_SRC}/llvm/utils/TableGen.
When looking at the code of a TableGen backend, here are a few things you should know:
The entry point is usually a
runmethod on the relatedXXXEmitterclass.The load-bearing records and classes are usually collected through calls to
RecordKeeper::getAllDerivedDefinitions; looking at the arguments of this function gives you the names of these records and classes.The helper structures used throughout the backends live in private headers under
${LLVM_SRC}/llvm/utils/TableGen/Common.
Overall, although what is generated by the TableGen backends may be complicated, following how they do the generation is relatively simple. First, they traverse some records stored in the main RecordKeeper object provided to them. Second, they generated the final output based on the values of the fields of these records.
In this section, you learned the basic skills required to approach an unknown TableGen backend. You saw that, if possible, you should use an existing user (i.e., an open source LLVM backend) of this backend as a template, and if this is not possible, you saw how to break down the problem into stages to isolate where the problem comes from. Finally, you got a few tips on how to approach the C++ code of a TableGen backend.
Summary
While we could spend a lot more time describing TableGen and its backends, we believe this chapter gave you enough material for you to get started in this space. Also, while understanding how a TableGen backend works can be satisfying, it is not required to write an LLVM backend. Hence, you just learned the basic skills that are necessary to write the inputs of these backends.
At this point, you may not feel comfortable writing records for a specific backend or know how the TableGen output of a backend fits into the LLVM infrastructure, and this is expected. You will grow more confident and accumulate this knowledge in the respective chapters when targeting these backends. However, now, you should feel confident looking at TableGen files (.td), and although you may not understand what the records are meant for, you should be able to predict what their content is.
In conclusion, you learned the following in this chapter:
What TableGen is and the general principle of how it is used in LLVM
How to read and write your first TableGen inputs
How the TableGen backends work and the basic structure of
their inputs, including where to find the load-bearing records and classes
their outputs, with their different sections guarded by macros
How to deal with errors with TableGen
This chapter concludes the basic knowledge you need to efficiently develop a backend with the LLVM infrastructure. In the next chapter, we will start to go deeper into the world of compilers by focusing our attention on understanding the LLVM IR.
Further reading
This chapter gave you a primer on TableGen. We did not cover things that you will probably never do, such as developing your own TableGen backend. If you want to explore TableGen-related topics in more detail, the LLVM’s documentation, while not perfect, covers some of these.
You can refer to the following:
An overview of TableGen at https://llvm.org/docs/TableGen/.
The full specification of the TableGen language at https://llvm.org/docs/TableGen/ProgRef.html.
The (succinct) documentation of the TableGen backends at https://llvm.org/docs/TableGen/BackEnds.html.
How to develop a TableGen backend at https://llvm.org/docs/TableGen/BackGuide.html. This one is also interesting if you want to debug a TableGen backend, since it presents the main classes available to handle records.
The command-line guide for the
llvm-tblgentool at https://llvm.org/docs/CommandGuide/tblgen.html.Finally, the compiler explorer website (https://godbolt.org/) features a TableGen mode for you to play with the TableGen syntax.
Before you finish this chapter, check out the quiz to test what you remember!
Quiz time
Now that you have completed reading this chapter, try answering the following questions to test your knowledge:
What does the following snippet do?
def;This creates an empty record, and TableGen automatically assigns it a unique name.
See the The TableGen programming language and Defining multiple records at once sections.
What would happen if we took the snippet featured in the Defining multiple records at once section and replaced the definition of the
ShippingPriceclass with the following snippet?
class ShippingPrice<int arg> {
int price = arg;
}We replaced the field named shippingPrice with a field named price. The new name now collides with the price field of record A. As a result, the value of record A's price will be overridden by the value of the price field of the ShippingPrice class.
See the The TableGen programming language section for more information.
How can you check whether a TableGen error comes from the frontend or the backend?
First, frontend errors usually report the filename, the line, and column numbers. Second, the frontend errors are not affected by the presence of/lack of -gen-xxx options.
See the Identifying the failing component section.
How would you approach working with an existing TableGen backend for the first time?
In a nutshell, you would look for another LLVM backend where this TableGen backend is used, read the comment in the main .td file that supports this TableGen backend, ask the community, and if necessary, look at the code of the TableGen backend.
See the Discovering a TableGen backend section.
How is the output of a TableGen backend typically structured?
The output of a TableGen backend is usually saved in a .inc file that is later included in various LLVM C++ files. The content of the file features several sections, each guarded by an ifdef macro.
See the The content of a generated file section.
To learn how to design instruction selectors, build legalizer stages, and debug backend passes with LLVM’s own reduction tools—check out LLVM Code Generation by Quentin Colombet, available from Packt. This 620-page comprehensive guide walks readers through the internals of LLVM’s backend infrastructure, from transforming IR to generating optimized machine code. With step-by-step examples, targeted exercises, and hands-on walkthroughs using TableGen, Machine IR, and GlobalISel, it’s both a reference and a roadmap for backend developers working on real-world architectures. Whether you’re building a custom target, contributing to LLVM itself, or deepening your compiler expertise, this book provides a practical foundation for mastering the backend.

Here is what some readers have said:


 | A guest post by
|