



ProgrammingPro #9: Macaw-LLM, A Complete Guide on LLMs, Pythonic Design Patterns, Python 3.12.0 Beta Release
Hi,
Happy Friday and welcome to another exciting issue of the ProgrammingPro! Today’s edition is loaded with deep dive guides including Large Language Models - A Complete Guide for anyone interested in learning the current state-of-art techniques for using LLMs, and Full Stack Developer Guide to guide you through essential dev concepts starting from basics.
You will also explore and take a look at trending AI tools and LLMs such as Guidance language to control Large Language Models (LLMs) and Macaw-LLM for multi-modal language modelling. In addition, we also have tutorial on Pythonic Design Patters, and an assortment of the most relevant industry insights and useful tools and resources for developers and software engineers.
Also, in today’s issue:
TechWave: News and Analysis
Secret Knowledge: Learning Resources
HackerHub: New AI/LLM Tools
Trending Research Papers
Tutorial: Pythonic Design Patterns
My promise with this newsletter is to act as your personal assistant and help you navigate and keep up-to-date with what's happening in the world of software development. What did you think of today's newsletter? Please consider taking the short survey below to share your thoughts and you will get a free PDF of the “The Applied Artificial Intelligence” eBook upon completion.
Thanks for reading.
Kartikey Pandey
Editor-in-Chief
Writer’s Credit: Special shout-out to Kirolos Youssef for his valuable contribution to this newsletter’s content!
Complete the Survey. Get a Packt eBook for Free!

⚡ TechWave: News and Analysis
Google’s AI-Boosted Search Engine: Google is undergoing the testing phase of an artificial intelligence-driven search functionality referred to as SGE (Search Generative Experience). Access is open to the public audience in order to test and evaluate the tool. The newly released feature will allow the audience to ask google any question and receive long-form answers with relevant resources.
Microsoft Dev Home: Microsoft introduced their new control center Microsoft Dev Home. The center is for windows users that allow programmers to track all their programming tasks and workflows in a single location. With the aid of the centralized dashboard, programmers can monitor coding tasks, GitHub issues, pull requests, available SSH connections, as well as system GPU, memory and network performance. While the service is currently in the preview phase, it is expected to be publicly launched in July.
Python 3.12.0 Beta Release: The public release of Python 3.12 beta 1 is now accessible. The programming language developers follow an annual release cycle for introducing new versions, divided into two phases. The first phase is in the first half of the year in beta releases, followed by the final release towards the end of the year. It is crucial to exercise caution while testing beta versions, as they aren’t stable versions. Developers are urged to try it out in a non-production environment to test how they can use the new features to enhance their codes.
Deno 1.34 Release: Deno is developed by the creator of Node.js. The main purpose of Deno is to provide an alternative to Node.js by addressing its limitations and security issues. Deno introduced the ability to compile projects into a single binary executable, enabling developers to distribute and execute binaries on all platforms without installing Deno dependencies. The latest release is now extended to cover NPM as well.
TypeScript 5.1 Release: TypeScript 5.1 has been announced. It comes with a host of new features such as snippet completions for @param JSDoc tags, easier implicit returns for undefined-returning functions, namescaped JSX attributes, and more.
AWS SDK for Go to Align with Go Release Policy: Starting later this year, the AWS SDK for Go will conform to Go's release policy by supporting the two latest generally available versions, with an extra six months added for good measure. This means Go 1.19 will be supported till February 2024, 1.20 till August 2024, and so on.
Secret Knowledge: Dev Learning Resources
Large Language Models - A Complete Guide: Here’s a great guide for anyone interested in learning the current state-of-art techniques for using LLMs effectively. It dives into training, optimizing, and unlocking the power of natural language processors. It explains the process of training LLMs, including data preparation, model architecture design, model training, evaluation, deployment, and monitoring in a production environment. It also dives into strategies to improve the accuracy, generalization ability, and performance of LLMs.
Launch HTTP Server in One Line of Python Code: In this tutorial, you will learn how to start a server with a single command line using python. In addition, you will be able to generate dynamic web content by executing scripts remotely and enhancing the security of your HTTP server by using encryption and generating self-signed digital certificates.
Understand QLoRA and How to Implement it: The NLP group at the University of Washington has introduced QLoRA, a technique used to achieve efficient finetuning of Language Models (LLMs) using less amount of memory. The article provides understanding of QLoRA, including its definition, installation process, getting started guide, and limitations. The repository, which includes a wide range of examples and code resources, can be found here.
Training your Own LLM using PrivateGPT: The main worry of using public AI services is the risk of exposing confidential company data to an external service provider. This is the main concern causing companies to step backward from adopting AI technologies. In this tutorial , we will learn about privatGPT , a Language Model (LLM) similar to Chat GPT. The main advantage is that it is based on your custom training data, without sacrificing data privacy.
Full Stack Developer Guide: If you want to become a Full Stack Developer but find yourself lost among the different resources or don’t know of where to begin, this step-by-step guide can work as your mentor. The newly released roadmap is specifically designed for absolute beginners. It guides you through each concept, starting from the very basics, with resources, examples, and projects at a detailed level.
Using k-Nearest Neighbors (kNN) in Python: In this video course, you’ll learn all about the k-nearest neighbors (kNN) algorithm in Python, including how to implement kNN from scratch. Once you understand how kNN works, you’ll use scikit-learn to facilitate your coding process.
Implementing a Distributed Key-Value Store in Go: This article is all about getting up to speed with the Raft consensus algorithm and goes into serious depth on using it along with Go as the basis for a distributed key-value store.
Google’s Large Sequence Models for Software Development: Google has recorded every change to its code base for decades, including rich descriptions, changes, and fixes. They treat this as a sequence modeling problem and create a set of robust internal tools that can help software engineers be more productive.

HackerHub: New AI/LLM Tools
Guidance by Microsoft: Guidance is a language to control Large Language Models (LLMs). It enables you to control modern language models more effectively and efficiently than traditional prompting or chaining. Guidance programs allow you to interleave generation, prompting, and logical control into a single continuous flow matching how the language model actually processes the text.
ChainForge: ChainForge is an open source visual programming environment for battle-testing prompts to LLMs. ChainForge is a data flow prompt engineering environment for analyzing and evaluating LLM responses.
Macaw-LLM: Macaw is a multi-modal language modeling by seamlessly combining image, video, audio, and text data, built upon the foundations of CLIP, Whisp.
griptape: A modular Python framework for LLM workflows, tools, memory, and data. griptape can be used to build sequential LLM pipelines and sprawling DAG workflows, augment LLMs with chain of thought capabilities and external tools, and add memory to AI pipelines.
Tempo: Tempo allows you to easily build & consume low-latency, cross-platform, and fully typesafe APIs.
Graph 0.20 - Generic Library for Creating Graph Data Structures: Graph supports different kinds of graphs such as directed graphs, acyclic graphs, or trees. It’s basically a library for creating generic graph data structures and modifying, analyzing, and visualizing them.
Trending Research Papers
Applying Machine Learning Analysis for Software Quality Test: Software Maintenance is considered one of the biggest running costs in software development product cycle. That’s why it is critical to understand what triggers maintenance and if bugs can be predicted. In this paper, an approach is developed to apply machine learning algorithms in order to determine the cumulative levels of software failures. The main goal is to find a method to accurately forecast software defects.
Self-Healing Software via Large Language Models & Formal Verification: This article presents a solution that integrates the capabilities of Large Language Models (LLMs) with Formal Verification techniques. The aim of this combination is to verify and automatically repair software vulnerabilities.
Requirements Engineering Framework for Human-centered AI Software Systems: Many of the AI solutions employed in software development tend to prioritize technical aspects and ignore critical human-centered aspects during requirement engineering. In this paper a new framework is developed based on human-centered AI guidelines and user surveys.The framework main goal is to facilitate the collection of requirements for human-centered-AI based software, bridging the gap between technical and human-centric perspectives.
Measuring the Impact of Programming Language Distribution: Available benchmarks used to evaluate neural code models typically concentrate on a limited range of programming languages, ignoring several popular ones like Go and Rust. This paper addresses this gap by introducing the BabelCode framework for execution-based evaluation of any benchmark in any language.
Tutorial: Pythonic Design Patterns
Design patterns are largely dependent on storing data; for this, Python comes bundled with several very useful collections. The most basic collections such as list, tuple, set, and dict will already be familiar to you, but Python also comes bundled with more advanced collections. Most of these simply combine the basic types for more powerful features. In this module, we will explain how to use these data types and collections in a Pythonic fashion.
Before we can properly discuss data structures and related performance, a basic understanding of time complexity (and specifically the big O notation) is required. The concept is really simple, but without it, I cannot easily explain the performance characteristics of operations and why seemingly nice-looking code can perform horribly.
Time complexity – The big O notation
This module uses the big O notation to indicate the time complexity for an operation. Feel free to skip this section if you are already familiar with this notation. While the notation sounds really complicated, the concept is actually quite simple.
When we say that a function takes O(1) time, it means that it generally only takes 1 step to execute. Similarly, a function with O(n) time would take n steps to execute, where n is generally the size (or length) of the object. This time complexity is just a basic indication of what to expect when executing the code, as it is generally what matters most.
The purpose of the big O notation is to indicate the approximate performance of an operation based on the number of steps that need to be executed. A piece of code that executes a single step 1,000 times faster but needs to execute O(2**n) steps will still be slower than another version of it that takes only O(n) steps for a value of n equal to 10 or more.
This is because 2**n for n=10 is 2**10=1024, which is 1,024 steps to execute the same code. This makes choosing the right algorithm very important, even when using languages such as C/C++, which are generally expected to perform better than Python with the CPython interpreter. If the code uses the wrong algorithm, it will still be slower for a non-trivial n.
For example, suppose you have a list of 1,000 items and you walk through them. This will take O(n) time because there are n=1000 items. Checking to see whether an item exists in a list means silently walking through the items in a similar way, which means it also takes O(n), so that’s 1,000 steps. If you do the same with a dict or set that has 1,000 keys/items, it will only take O(1) step because of how a dict/set is structured.
This means that if you want to check the existence of 100 items in that list or dict, it will take you 100*O(n) for the list and 100*O(1) for the dict or set. That is the difference between 100 steps and 100,000 steps, which means that the dict/set is n or 1,000 times faster in this case.
Even though the code seems very similar, the performance characteristics vary enormously:
>>> n = 1000
>>> a = list(range(n))
>>> b = dict.fromkeys(range(n))
>>> for i in range(100):
... assert i in a # takes n=1000 steps
... assert i in b # takes 1 step
To illustrate O(1), O(n), and O(n**2) functions:
>>> def o_one(items):
... return 1 # 1 operation so O(1)
>>> def o_n(items):
... total = 0
... # Walks through all items once so O(n)
... for item in items:
... total += item
... return total
>>> def o_n_squared(items):
... total = 0
... # Walks through all items n*n times so O(n**2)
... for a in items:
... for b in items:
... total += a * b
... return total
>>> n = 10
>>> items = range(n)
>>> o_one(items) # 1 operation
1
>>> o_n(items) # n = 10 operations
45
>>> o_n_squared(items) # n*n = 10*10 = 100 operations
2025
To illustrate this, we will look at some slower-growing functions first:
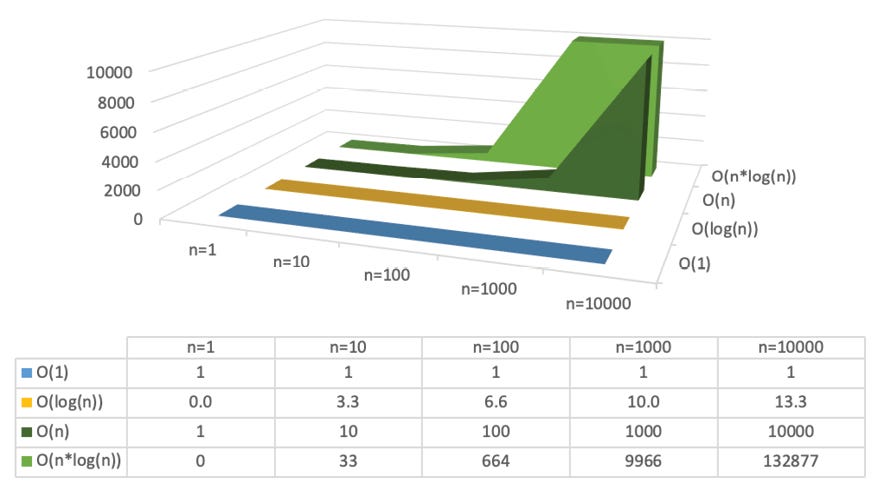
As you can see, the O(log(n)) function scales really well with larger numbers; this is why a binary search is so incredibly fast, even for large datasets.
This tutorial is a content extract from the book Mastering Python - Second Edition written by Rick van Hattem and published by Packt Publishing.