

ProgrammingPro #7: Numbers Every LLM Developer Should Know, LMQL,100 Python Code Snippets, and pandas-ai
Hi,
I hope you’ve been doing well! Today we are exploring:
News and Analysis
Community Resources and Secret Knowledge
Prompt Engineering Guides
Tutorial: Learning About Multi-Tier Architectures
In this latest ProgrammingPro edition, we also detail Numbers Every LLM Developer Should Know, 100 Python Code Snippets for Everyday Problems, LMQL, and pandas-ai.
My promise with this newsletter is to act as your personal assistant and help you navigate and keep up-to-date with what's happening in the world of software development. What did you think of today's newsletter? Please consider taking the short survey below to share your thoughts and you will get a free PDF of the “The Applied Artificial Intelligence” eBook upon completion.
Until next time!
Kartikey Pandey
Editor-in-Chief
Complete the Survey. Get a Packt eBook for Free!
News and Analysis
Google Introduces Colab AI: Using Codey, a family of code models built on PaLM 2, Colab will soon add AI coding features like code completions, natural language to code generation and a code-assisting chatbot. Plus, the versions of Codey being used to power Colab have been customized especially for Python and for Colab-specific uses. Anyone with an internet connection can access Colab, and use it free of charge. Millions of students use Colab every month to learn Python programming and machine learning.
Go Developer Survey 2023 Q1 Results: Nearly 6,000 gophers took part in the latest developer survey, and now we have the results. Key takeaways include:
92% of respondents are satisfied using Go.
Error handling is now folks' biggest pain point.
Keeping dependencies up to date (if maintaining a module) is a challenge.
VS Code remains the editor of choice, with GoLand a solid second.
The majority of Go devs work on either a Mac or Linux machine (tied in terms of popularity) but Windows is notably popular with newer devs.
Smol Developer: Your very own personal junior developer. This is a prototype of a "junior developer" agent (aka smol dev) that scaffolds an entire codebase out for you once you give it a product spec, but does not end the world or overpromise AGI. Instead of making and maintaining specific, rigid, one-shot starters, like create-react-app, or create-nextjs-app, this is basically create-anything-app where you develop your scaffolding prompt in a tight loop with your smol dev.
Spring Batch 5.0.2 available now - Spring Batch 5.0.2 is now available from Maven Central. This release resolves 25 issues, including bug fixes, enhancements, documentation updates and dependency updates. For more details about the changes, please refer to the change log.
OpenAI’s CEO Urges Congress to Regulate AI: OpenAI CEO Sam Altman has urged US lawmakers to regulate AI and form an agency to license AI companies. Altman acknowledged the transformative potential of AI but also warned of its potential misuse like manipulating public opinion.
Google’s New AI Model Uses 5 Times Text Data Than Predecessor: Google’s new large language model, PaLM 2, which the company announced last week, uses almost five times as much training data as its predecessor from 2022, allowing its to perform more advanced coding, math and creative writing tasks.
✨ Community Resources & Secret Knowledge
100 Python Code Snippets for Everyday Problems: Throughout this article, you’ll find a whole host of Python code snippets. Each of these code snippets are extracted from the website’s How to Python series. Naturally, there has been a bit of a push to create a GitHub repo for all of these snippets.
100 C# Code Snippets for Everyday Problems: As developers, we often seek practical solutions to common challenges, and C# provides a powerful and versatile platform for addressing everyday issues. This article is a collection of C# code snippets that cover a wide range of scenarios you might encounter during software development.
pandas-ai - Integrate Generative AI Into Pandas: Pandas AI is a Python library that adds generative artificial intelligence capabilities to Pandas, the popular data analysis and manipulation tool. It is designed to be used in conjunction with Pandas, and is not a replacement for it.
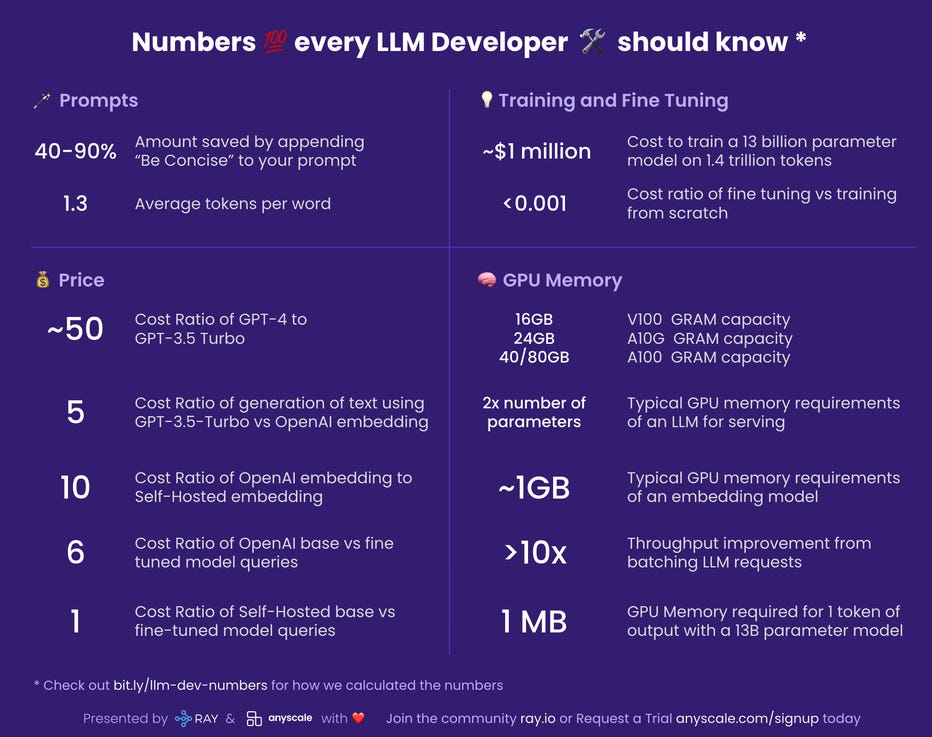
Numbers Every LLM Developer Should Know: This article discusses a set of numbers for LLM developers to know that are useful for back-of-the envelope calculations.
LMQL: LMQL is a query language for large language models (LLMs). It facilitates LLM interaction by combining the benefits of natural language prompting with the expressiveness of Python. With only a few lines of LMQL code, users can express advanced, multi-part and tool-augmented LM queries, which then are optimized by the LMQL runtime to run efficiently as part of the LM decoding loop. Explore the GitHub repository here.
A 9-Hour Go Course for Beginners: You might find this practical and project oriented useful as a refresher or to pass on to someone else in your team.
📚 Prompt Engineering Guides
Prompt Engineering Guide: Researchers use prompt engineering to improve the capacity of LLMs on a wide range of common and complex tasks such as question answering and arithmetic reasoning. Developers use prompt engineering to design robust and effective prompting techniques that interface with LLMs and other tools. This guide covers the basics of prompts to provide a rough idea of how to use prompts to interact and instruct LLMs.
Brex’s Prompt Engineering Guide: This guide is based on lessons learned from researching and creating Large Language Model (LLM) prompts for production use cases at Brex. It covers the history around LLMs as well as strategies, guidelines, and safety recommendations for working with and building programmatic systems on top of large language models, like OpenAI's GPT-4.
50 ChatGPT Prompts Every Software Developer Should Know: This article explores awesome ChatGPT-4 prompts specifically tailored for software developers. These prompts can assist with tasks such as code generation, code completion, bug detection, code review, API documentation generation, and more.
Tutorial: Learning About Multi-Tier Architectures
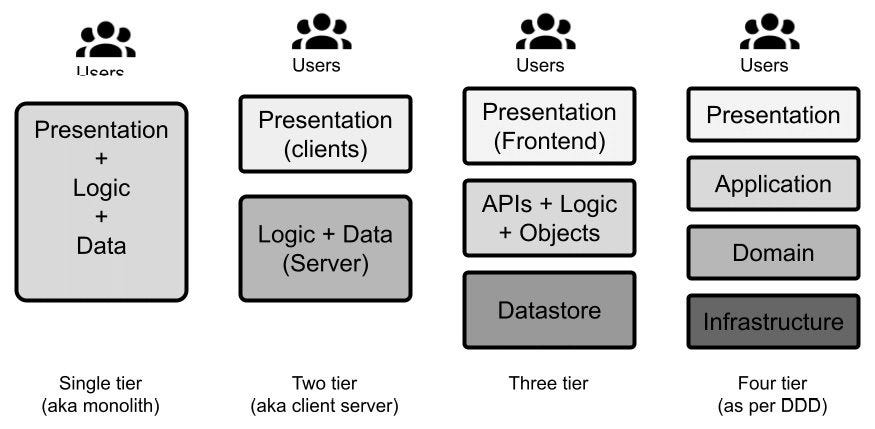
Multi-tier architectures, also known as n-tier architectures, are a way to categorize software architectures based on the number and kind of tiers (or layers) encompassing the components of such a system. A tier is a logical grouping of the software components, and it's usually also reflected in the physical deployment of the components. One way of designing applications is to define the number of tiers composing them and how they communicate with each other. Then, you can define which component belongs to which tier. The most common types of multi-tier applications are defined in the following list:
The simplest (and most useless) examples are single-tier applications, where every component falls into the same layer. So, you have what is called a monolithic application.
Things get slightly more interesting in the next iteration, that is, two-tier applications. These are commonly implemented as client-server systems. You will have a layer including the components provided to end users, usually through some kind of graphical or textual user interfaces, and a layer including the backend systems, which normally implement the business rules and the transactional functionalities.
Three-tier applications are a very common architectural setup. In this kind of design, you have a presentation layer taking care of interaction with end users. We also have a business logic layer implementing the business logic and exposing APIs consumable by the presentation layer, and a data layer, which is responsible for storing data in a persistent way (such as in a database or on a disk).
More than three layers can be contemplated, but that is less conventional, meaning that the naming and roles may vary. Usually, the additional tiers are specializations of the business logic tier, which was seen in the previous point. The following diagram illustrates an example of a multi-tier architecture:
The advantages of a multi-tier approach are similar to those that you can achieve with the modularization of your application components. Some of the advantages are as follows:
The most relevant advantage is probably scalability. This kind of architecture allows each layer to scale independently from each other. So, if you have more load on the business (or frontend, or database) layer, you can scale it (vertically, by adding more computational resources, or horizontally, by adding more instances of the same component) without having a huge impact on the other components. And that is also linked to increased stability overall: an issue on one of the layers is not so likely to influence the other layers.
Another positive impact is improved testability. Since you are forced to define clearly how the layers communicate with each other (such as by defining some APIs), it becomes easier to test each layer individually by using the same communication channel.
Modularity is also an interesting aspect. Having layers talking to each other will enforce a well-defined API to decouple each other. For this reason, it is possible (and is very common) to have different actors on the same layer, interacting with the other layer. The most widespread example here is related to the frontend. Many applications have different versions of the frontend (such as a web GUI and a mobile app) interacting with the same underlying layer.
Last but not least, by layering your application, you will end up having more parallelization in the development process. Sub teams can work on a layer without interfering with each other. The layers, in most cases, can be released individually, reducing the risks associated with a big bang release.
There are, of course, drawbacks to the multi-tier approach, and they are similar to the ones you can observe when adopting other modular approaches, such as microservices. The main disadvantage is to do with tracing.
It may become hard to understand the end-to-end path of each transaction, especially (as is common) if one call in a layer is mapped to many calls in other layers. To mitigate this, you will have to adopt specific monitoring to trace the path of each call; this is usually done by injecting unique IDs to correlate the calls to each other to help when troubleshooting is needed (such as when you want to spot where the transactions slow down) and in general to give better visibility into system behavior.
This tutorial is a content extract from the book Hands-On Software Architecture with Java written by Giueseppe Bonocore and published by Packt Publishing.