

Merkle Trees and Anti-Entropy — Concepts and Implementation
How Distributed Systems Like Cassandra and DynamoDB Stay Consistent at Scale — And How You Can Build It Too

Have you ever gone on a road trip with friends and tried to split expenses? It’s fun — until someone gets stuck doing the dirty work of tracking who owes what. Picture this: you’re in a group of five, each person tallying their own totals. When it’s time to settle up, you don’t want to compare receipts line by line with everyone, every day. Instead, you check the overall totals. If someone’s number doesn’t match, you know there’s a discrepancy — so you only compare details with the friend who has a different total. Efficient, right?
Now, scale up this problem. Imagine a massive distributed system where 10GB of data lives on each node, and every bit is replicated across five different nodes for reliability. When a network partition occurs and a node comes back online, is it really practical to sync all 10GB of data across every node, every time? Of course not.
This is the very challenge that engineers at Cassandra, DynamoDB, and even in blockchain technology have faced. How do you quickly identify and fix just the pieces of data that have changed, without wasting massive amounts of time and bandwidth checking everything, everywhere?
The secret lies in two powerful concepts: Merkle trees and anti-entropy protocols.
In this article, we’ll step into an engineer’s shoes — exploring how these data structures and algorithms allow distributed databases like DynamoDB and Cassandra to efficiently detect, compare, and synchronize changes. We’ll break down what Merkle trees and anti-entropy actually are, why they matter, and how you can implement them yourself (with hands-on examples in Golang).
Ready to see how modern distributed systems stay fast and consistent, even at a massive scale? Let’s dive in!
Understanding Merkle Trees
Imagine you’re the head of accounting at a global company with offices in 100 cities worldwide. Your responsibility: keep track of all expenses across every location. Reconciling records for every single office, every time, would be a logistical nightmare — not to mention a massive waste of time and resources.
To solve this, you create a smarter system:
Instead of checking every office one by one, you appoint an assistant who keeps a running total.
Now, you only compare your assistant’s master total with your own. If the totals match, you’re in sync. If not, you zero in on where the change happened.
Taking it further, you group offices by regions (say, Asia-Pacific and USA). Each region reports upward. When there’s a mismatch, you drill down region by region, then country, then city.
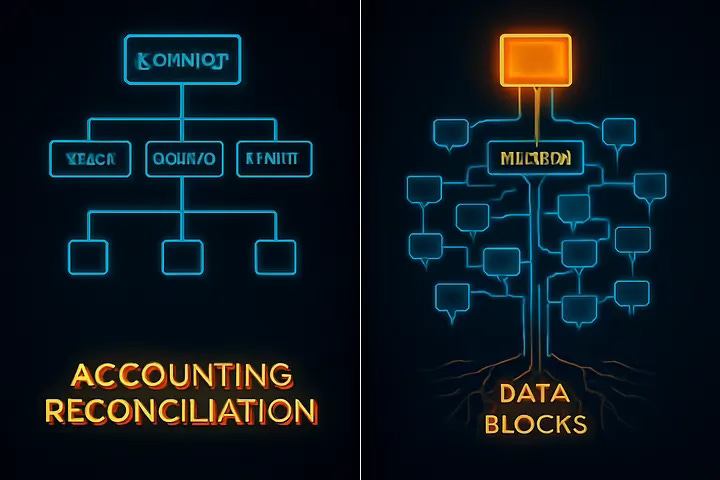
This hierarchical, divide-and-narrow approach is precisely how Merkle trees work in distributed systems.
What is a Merkle Tree?
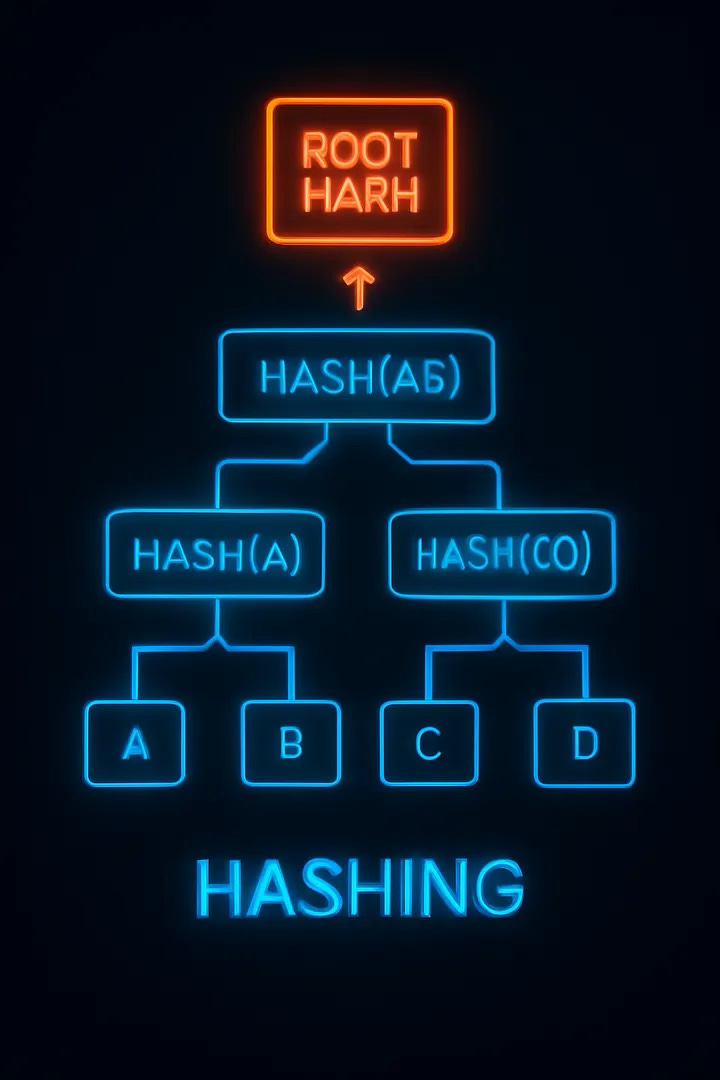
A Merkle tree is a data structure designed for efficient and secure verification of large sets of data. Here’s the basic anatomy:
Leaf Nodes: Each one holds a hash of actual data — like an office’s transactions.
Internal (Branch) Nodes: Each combines and hashes its children’s hashes, summarizing everything below.
Root Node: The master hash — changing if anything underneath changes.
Key insight: Instead of comparing all data, you compare hashes at each level, honing in only where there’s a mismatch. This scales logarithmically, not linearly.
Historical Context:
Devised by Ralph Merkle in 1979, Merkle trees are now central to blockchains, distributed file systems, and database consistency.
How Merkle Trees Work
a. The Hashing Process
Hashing the Leaves: Pass each data item (file, transaction, etc.) through a hash function (e.g., SHA-256). These are the leaf nodes.
Building Up the Tree: Pair up the leaf hashes, concatenate and hash again to form parents, repeating until you reach the root.
Checking for Changes: Any single data change changes its hash and all parents up to the root. Comparing roots lets you instantly check if two datasets match.
b. Example: Tiny Merkle Tree
Suppose you have four data blocks: A, B, C, D.
Step 1: Hash each block.
Step 2: Hash pairs: (A+B), (C+D).
Step 3: Hash those two: (AB + CD) = Root.
If just B changes, only three hashes need recalculating, and you can precisely spot the change.
Real-World Applications of Merkle Trees
Blockchains: Store all transactions for a block as a Merkle tree. The root in the block header allows anyone to verify a transaction’s inclusion.
Versioned File Systems (e.g., Git): Every commit is represented as a Merkle root; differences between commits highlight only what’s changed.
Distributed Databases (Cassandra, DynamoDB): Use Merkle trees for anti-entropy. Only out-of-sync segments are reconciled, not the full dataset.
Merkle trees guarantee tamper-evidence and make large-scale, bandwidth-efficient consistency possible.
What is Anti-Entropy?
Back to our global accounts team: over time, small differences creep into each office’s ledger — network delays, miscommunications, independent corrections. These inconsistencies, or entropy, must be regularly tracked down and fixed.
Anti-entropy is your systematic, efficient approach to reconciling just the differences, not everything.
Anti-Entropy Mechanisms
Gossip Protocols: Random offices synchronize with each other, gradually spreading updates network-wide.
Vector Clocks: Track who changed what, and when, to resolve conflicts precisely.
Merkle Trees: Group and summarize records as hashes; compare just summaries first to find divergences efficiently.

How Merkle Trees Empower Anti-Entropy in Real Systems
This is exactly the strategy used by distributed databases like Cassandra and DynamoDB. Each node in the system summarizes its stored data using a Merkle tree. When it’s time to reconcile — maybe after a network glitch or data loss — nodes quickly compare root hashes, then only dive deeper where discrepancies are found. This process scales effortlessly, allowing massive companies (and databases) to keep their records in harmony with minimal effort.
So, instead of drowning in a sea of spreadsheets, your accounts team uses anti-entropy protocols — and especially Merkle trees — to work smarter, not harder, keeping the entire global ledger consistent, up-to-date, and audit-ready.
In essence:
Anti-entropy, led by the power of Merkle trees, turns the messy challenge of financial reconciliation across a giant organization into a fast, targeted process — ensuring global consistency with a fraction of the work. This is the same magic powering reliable, scale-proof distributed databases today.
Implementing a Merkle Tree in Code
To truly appreciate the power of Merkle trees in distributed systems, let’s walk through a practical implementation in Go. This example captures the fundamental operations: building the tree, generating cryptographic hashes, and efficiently identifying differences between trees.
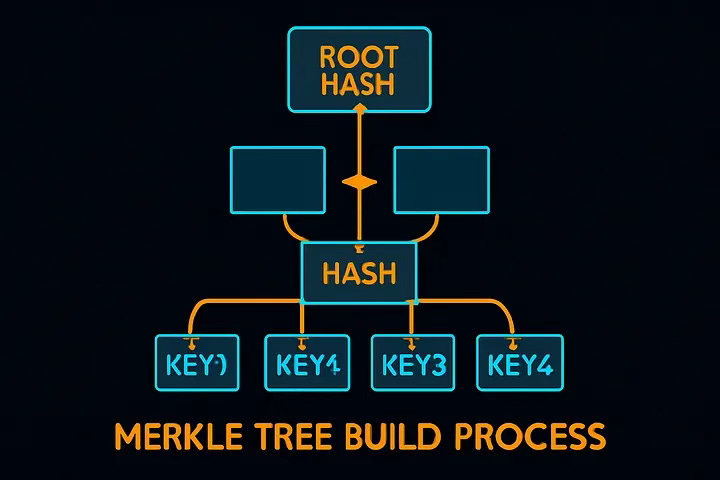
Building the Merkle Tree
At the core, a Merkle tree organizes data blocks into a hierarchical hash structure. Our implementation breaks down like this:
We start by dividing data into buckets (or partitions), each containing a fixed number of keys.
Each bucket’s combined data is hashed, creating a leaf node.
We then recursively pair leaf nodes, concatenate their hashes, and hash again to form parent nodes.
This process repeats until a single root node remains, representing a compact summary of the entire dataset.
Here’s how these pieces fit together in code:
// MerkleNode represents a leaf or internal node with its hash and children.
type MerkleNode struct {
Hash string
Left *MerkleNode
Right *MerkleNode
KeyRange []string // Only non-empty for leaves, marks keys covered
}
// Tree manages the Merkle tree for a dataset or node partition.
type Tree struct {
BucketSize int // Number of keys per leaf bucket
Root *MerkleNode
mu sync.RWMutex // Protects concurrent access
}When you call the Build method with sorted keys and their corresponding data, it hashes data bucket by bucket to create leaves:
func (t *Tree) buildLeaves(keys []string, kvs map[string][]byte) []*MerkleNode {
var leaves []*MerkleNode
for i := 0; i < len(keys); i += t.BucketSize {
end := min(i + t.BucketSize, len(keys))
bucket := keys[i:end]
// Concatenate keys and their values (hex encoded)
data := “”
for _, k := range bucket {
data += k + “:” + hex.EncodeToString(kvs[k])
}
h := sha256.Sum256([]byte(data))
leaves = append(leaves, &MerkleNode{
Hash: hex.EncodeToString(h[:]),
KeyRange: bucket,
})
}
return leaves
}The buildMerkle function then recursively builds parents by hashing pairs of child hashes, gracefully handling odd numbers of nodes:
func buildMerkle(nodes []*MerkleNode) *MerkleNode {
if len(nodes) == 0 {
return nil
}
if len(nodes) == 1 {
return nodes[0]
}
var parents []*MerkleNode
for i := 0; i < len(nodes); i += 2 {
if i+1 < len(nodes) {
data := nodes[i].Hash + nodes[i+1].Hash
h := sha256.Sum256([]byte(data))
parents = append(parents, &MerkleNode{
Hash: hex.EncodeToString(h[:]),
Left: nodes[i],
Right: nodes[i+1],
})
} else {
parents = append(parents, nodes[i])
}
}
return buildMerkle(parents)
}After building, the single root hash summarizes the whole dataset:
func (t *Tree) RootHash() string {
t.mu.RLock()
defer t.mu.RUnlock()
if t.Root == nil {
return “”
}
return t.Root.Hash
}Comparing Trees to Identify Differences
One of the biggest benefits of Merkle trees is their ability to efficiently detect exactly where two datasets differ — without scanning everything. This is done by recursively comparing node hashes from the roots downward:
// Diff returns key ranges that differ between two Merkle trees.
func (t *Tree) Diff(other *Tree) ([][]string, error) {
t.mu.RLock()
defer t.mu.RUnlock()
if t.Root == nil || other.Root == nil {
return nil, errors.New(”cannot diff: tree(s) not built”)
}
diffs := make([][]string, 0)
diffHelper(t.Root, other.Root, &diffs)
return diffs, nil
}
// Helper to recursively collect differing leaf key ranges.
func diffHelper(a, b *MerkleNode, diffs *[][]string) {
if a == nil || b == nil {
return
}
if a.Hash == b.Hash {
return // subtree matches; no difference
}
if a.Left == nil && a.Right == nil && b.Left == nil && b.Right == nil {
// Both leaves differ; record key range
*diffs = append(*diffs, a.KeyRange)
return
}
if a.Left != nil && b.Left != nil {
diffHelper(a.Left, b.Left, diffs)
}
if a.Right != nil && b.Right != nil {
diffHelper(a.Right, b.Right, diffs)
}
}This targeted approach means two large datasets can reconcile efficiently by syncing only the data within the mismatched key ranges.
Summary
This Go implementation demonstrates how Merkle trees:
Build a cryptographic hash tree from raw data in buckets to leaves to root.
Provide a single summary root hash for efficient data verification.
Enable fast difference detection by recursive hash comparison, isolating only exact data shards that need syncing.
Understanding and implementing these core operations is the first step toward applying Merkle trees for secure, scalable data consistency in real distributed systems.
Using Merkle Trees for Anti-Entropy: Step-by-Step
Each node builds its Merkle tree over its dataset.
Nodes exchange root hashes. If equal, they’re in sync; if not, mismatches exist.
Compare children hashes recursively until you reach mismatched leaves.
Sync only the data for mismatched leaves, not the entire dataset.
Rebuild trees and repeat as needed. This gives you fast, granular repair.

Performance Considerations
Efficiency:
Merkle trees transform O(n)O(n) comparisons into O(logn)O(logn), minimizing bandwidth and compute, critical at scale.
Trade-offs:
Depth & Bucket Size: Small buckets yield deep trees and fine granularity for repairs; large buckets are faster to build but coarser.
Branching Factor: Binary is simple, but higher factors further reduce tree height.
Hash Function: Use cryptographic hashes for security, but know they’re slower than simple checksums.
Best Practices:
Keep keys sorted and buckets consistent.
Regularly audit cryptographic choice and correctness.
Avoid over-deep trees or inconsistent bucketing, as these kill performance.
Case Study: Cassandra’s Anti-Entropy Repair
Scenario: A network partition causes one node to lag. When it rejoins, Cassandra must reconcile data — efficiently.
Process:
Each node builds a Merkle tree for a partition.
Nodes exchange Merkle roots; if mismatched, they compare subtrees.
Drill down recursively until mismatching leaves found; sync only those ranges.
Visual Flow:
Build trees
Exchange and compare roots
Drill to mismatched children
Sync only affected ranges

Conclusion
Merkle trees are the backbone of fast, scalable, and resilient data synchronization in distributed systems. They enable efficient, targeted anti-entropy repairs, keeping massive databases like Cassandra and DynamoDB consistent with minimal overhead — even in the face of network partitions or data loss.
As data volumes grow and systems span continents, intelligent anti-entropy protocols will only become more crucial. The future? Expect even tighter cryptographic guarantees, hybrid data structures, and smarter reconciliation engines — keeping the world’s distributed data trustworthy and lightning-fast.
Stay Connected!
💡 Follow me on LinkedIn: Archit Agarwal
🎥 Subscribe to my YouTube: The Exception Handler
📬 Sign up for my newsletter: The Weekly Golang Journal
✍️ Follow me on Medium: @architagr
👨💻 Join my subreddit: r/GolangJournal
💡 Follow me on Twitter: @architagr