

Integrating Events with CQRS
An Excerpt from “Chapter 7: Integrating Events with CQRS” in the book Domain-Driven Refactoring by Alessandro Colla and Alberto Acerbis (Packt, May 2025)


In this chapter, we will explore how to effectively integrate events into your system using the Command Query Responsibility Segregation (CQRS) pattern. As software architectures shift from monolithic designs to more modular, distributed systems, adopting event-driven communication becomes essential. This approach offers scalability, decoupling, and resilience, but also brings complexity and challenges such as eventual consistency, fault tolerance, and infrastructure management.
The primary goal of this chapter is to guide you through the implementation of event-driven mechanisms within the context of a CQRS architecture. By the end of this chapter, you will have a clear understanding of how events and commands operate in tandem to manage state changes, communicate between services, and optimize both the reading and writing of data.
(In this excerpt) you will learn about the following:
The benefits and trade-offs of transitioning from synchronous to asynchronous communication
How event-driven architectures improve system scalability and decoupling
The difference between commands (which trigger state changes) and events (which signal that something has happened)
How to apply proper message-handling patterns for both
The principles of CQRS and understanding why separating read and write models enhances performance and scalability
How to implement the separation of command and query responsibilities with a focus on read and write optimization
How to introduce a message broker for handling asynchronous communication
How to capture and replay the history of state changes with event sourcing
…
The complete code for this chapter can be found within the 02-monolith_with_cqrs branch and the 03-monolith_with_cqrs_and_event_sourcing branch within the book’s GitHub repository.
Understanding the role of messages in a modular monolith
One of the fundamental steps in moving from a monolithic architecture to a microservice-based solution is to adopt events to facilitate communication between different modules. Introducing events into a modular architecture can significantly enhance the design by enabling systems to be more loosely coupled, scalable, and reactive. Of course, as discussed in previous chapters, every architectural change comes with trade-offs. Replacing synchronous communication with asynchronous event-based messaging introduces a new set of challenges, which can be summarized as shown in Table 7.1:
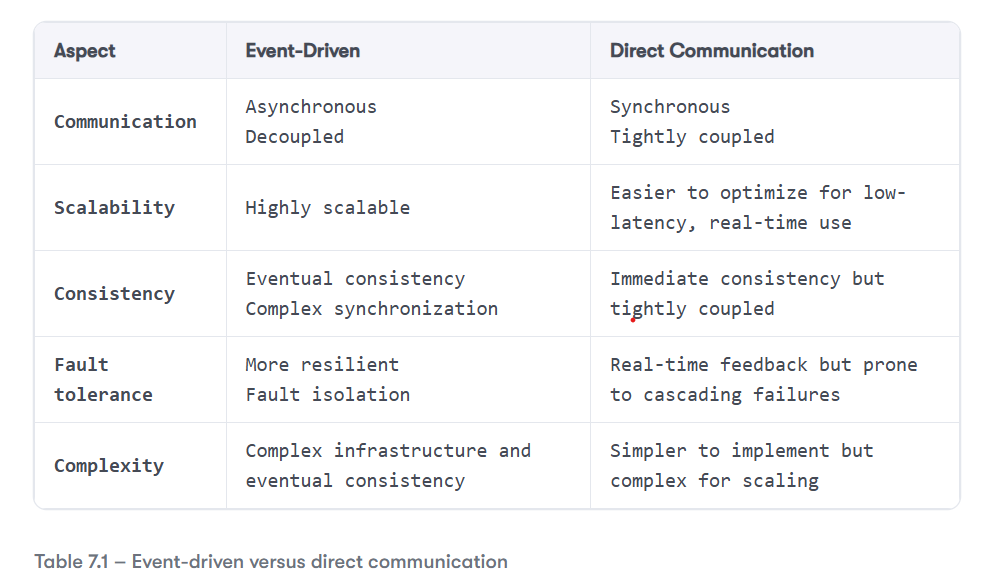
As you can see, introducing events into an application requires careful consideration of the pros and cons, since this choice fundamentally alters how different parts of your system interact. Your code base will evolve to accommodate these changes, which can affect the way you handle data consistency, fault tolerance, and scalability.
But before diving into the code to see how events reshape your application, it is important to understand the different types of messages and their specific purpose within this architecture.
Commands versus events
It is crucial to distinguish between the different types of messages in your system, as each serves a distinct purpose and requires different handling patterns. Commands are messages that change the state of an aggregate. These are direct instructions that typically represent user actions or business requests, such as placing an order or updating its state. On the other hand, events are messages that notify other parts of the system that something has happened, such as an order being placed or a payment being accepted, but they do not alter the aggregate’s state.
While we will dive deeper into these concepts in the following sections, it is important to understand the different messaging patterns you need to apply depending on the message type. Commands usually follow a fire-and-forget pattern. A command is sent to a specific component that is responsible for executing it, ensuring that the requested action is performed.
To ensure reliable processing of commands—especially in asynchronous systems—the send-receive pattern or the producer-consumer pattern is often used. In this pattern, a producer sends a command message, which is then consumed and processed by one or more consumers. Figure 7.1 illustrates this pattern.

Figure 7.1 – Producer-consumer pattern
In contrast, events are handled using a publish-subscribe pattern, where the event is published and multiple components interested in this event can subscribe and react to it independently. Figure 7.2 shows the publish-subscribe pattern. Each published message is made available to each subscription registered with the topic.

Figure 7.2 – Publish-subscribe pattern
Recognizing these differences will help you select the appropriate messaging pattern for each scenario, ensuring your system is designed efficiently and operates in a predictable manner.
Understanding the different types of messages in your system is crucial, as they directly reflect the business intent in your code, as you discovered in the EventStorming subsection in Chapter 2, Understanding Complexity: Problem and Solution Space.
By appropriately using message types, you replicate the business intent within your application architecture, enabling a clearer alignment between the business process and the code. For instance, implementing commands ensures that actions are executed as intended, while events allow for the decoupling of components, facilitating communication across the system. Recognizing the publish-subscribe pattern for events will help maintain a robust and responsive system that mirrors the underlying business logic.
When designing a system using commands and events, it is essential that the naming of each message clearly conveys its business intent. The name of a message should instantly communicate whether it is meant to trigger an action or report a past occurrence, ensuring your code is easy to understand and maintain.
For commands, the name should be in the imperative form, as they represent requests or instructions for actions that need to be executed. A command tells the system what the user or business process wants to happen. Look at the following command from our ERP example project:
public class CreateSalesOrder(SalesOrderId aggregateId,
Guid commitId,
SalesOrderNumber salesOrderNumber,
OrderDate orderDate,
CustomerId customerId,
CustomerName customerName,
IEnumerable<SalesOrderRowDto> rows)
: Command(aggregateId, commitId)
{
public readonly SalesOrderId SalesOrderId = aggregateId;
public readonly SalesOrderNumber SalesOrderNumber = salesOrderNumber;
public readonly OrderDate OrderDate = orderDate;
public readonly CustomerId CustomerId = customerId;
public readonly CustomerName CustomerName = customerName;
public readonly IEnumerable<SalesOrderRowDto> Rows = rows;
}The name of the command, CreateSalesOrder, makes the intent clear: The user wants to create a new order. Other than that, there are other important aspects in this class, but for now, it is important to pay attention to its name.
For events, the name should be in the past tense because they represent something that has already happened in the system. Events notify other parts of the system that a particular business operation has been completed. The following is the event related to the command shown before:
public sealed class SalesOrderCreated(SalesOrderId aggregateId,
Guid commitId,
SalesOrderNumber salesOrderNumber,
OrderDate orderDate,
CustomerId customerId,
CustomerName customerName,
IEnumerable<SalesOrderRowDto> rows) : DomainEvent(aggregateId, commitId)
{
public readonly SalesOrderId SalesOrderId = aggregateId;
public readonly SalesOrderNumber SalesOrderNumber = salesOrderNumber;
public readonly OrderDate OrderDate = orderDate;
public readonly CustomerId CustomerId = customerId;
public readonly CustomerName CustomerName = customerName;
public readonly IEnumerable<SalesOrderRowDto> Rows = rows;
}The name of the event, SalesOrderCreated, clearly indicates that the action has already occurred, allowing subscribers to react accordingly. This makes the event’s purpose explicit and easy to understand.
By using the imperative form for commands and the past tense form for events, you not only make the business intent explicit in your code but you also create a common language between developers and domain experts, ensuring consistency and clarity throughout the system. Remember what we discussed about ubiquitous language in the section titled Defining terms clearly will solve half of the problem in Chapter 3, Strategic Patterns.
Domain and integration events
Now that you understand the difference between commands and events, it is time to take things a step further. While the primary purpose of an event is to notify other parts of the system that a particular business operation has been completed, not all parts of the system should receive this notification. Because an event carries important business information, it must be treated carefully. Specifically, we need to differentiate between events that belong within a bounded context and those that can be shared across contexts.
A domain event is an event that captures something meaningful that happened within a specific bounded context. These events express business intent and are often tied closely to the internal logic and rules of that context. Since each bounded context operates with its ubiquitous language and domain model, domain events are typically meant to stay within the boundaries of that context, ensuring that the integrity of the model is preserved without unnecessary coupling to the other parts of the system.
However, some events need to be shared between bounded contexts, especially when the actions in one context impact another. In this case, we use integration events. These events are designed to share information across contexts or even systems, without tightly coupling them. An integration event should contain only the essential data needed by other contexts to react to it while keeping the contexts independent. By carefully identifying which events should stay local (domain events) and which can be shared (integration events), you can avoid unnecessary coupling and ensure that the boundaries between contexts are respected.

Understanding this distinction helps ensure that your system stays modular and scalable and maintains a clear separation of concerns.
When transitioning your code base to asynchronous communication, it becomes necessary to introduce a message broker into your system. In an event-driven architecture, the broker acts as an intermediary that ensures events are properly delivered to the appropriate consumers, enabling components to communicate asynchronously without needing direct interaction.
We will dive deepter into this topic in Chapter 11, Dealing with Events and Their Evolution .
Separating command and query responsibilities
Before jumping to the implementation of events in the monolith, let’s look at CQRS. This concept was introduced in the Towards cleaner and more maintainable code section in Chapter 5, Introducing Refactoring Principles. To review the flow of CQRS, you can refer to Figure 5.6 in the same section. So, if you need a refresher on its origin and fundamental workings, go back for a quick review before reading further.
In Chapter 6, Transitioning from Chaos, we started refactoring our monolith, and the last thing missing is to implement CQRS without events yet.
The key concept of CQRS is the separation of responsibilities of reading and writing data within a system. In a typical application, the same model is often used for both querying (reading) and updating (writing) data. However, with CQRS, these concerns are separated into distinct models; the command model (write model) is responsible for handling commands, which are operations that change the state of the system (e.g., creating, updating, or deleting records) and the query model (read model) is optimized for reading data and retrieving information. The query model can be structured differently from the write model to support efficient queries, often focusing on the performance and scalability of read operations.
By separating these responsibilities, CQRS allows each model to be optimized independently. For example, the read model might denormalize data to make querying faster, while the write model can remain normalized to ensure consistency during updates. So, CQRS encourages the use of distinct models for reads and writes, which can lead to better scalability, maintainability, and performance in complex systems. Figure 7.3 shows how a CQRS application works.

Figure 7.3 – A CQRS application’s working
What you should have noticed immediately is that we have two distinct databases (schemas): one for the write model and one for the read model. Be aware that this does not mean that you should also have two distinct database instances. You could have just one instance of your database server with two different schemas in it (the databases).
Another important thing to keep in mind is the choice of the synchronization option between the two models. There are various ways to achieve that and, maybe, the most efficient is by using event sourcing. Using events to communicate the domain’s state changes allows us to achieve better scalability and performance in a distributed or high-traffic system. The trade-off, because you know there is no silver bullet, is called eventual consistency. Eventual consistency means that we accept that data may be temporarily inconsistent between the write and read models but guarantees that all parts of the system will eventually reflect the latest state.
There are several strategies to synchronize the write and read models, each with its own trade-offs in terms of complexity, consistency, and performance. Before introducing event-based synchronization, let’s first explore simpler approaches—starting with direct database synchronization—before moving on to options like database polling, materialized views, shared databases, and database triggers.
Direct database synchronization
Direct database synchronization involves synchronous dual writes, where the write model (command handler) directly updates both the write store and the read store at the same time when processing a command. For example, when a command updates the state (e.g., changing a user profile), the system can immediately update both the write database and the read database.
To maintain consistency, both the write and read models must be updated atomically in the same transaction, or compensating actions (rollback) should be implemented in case one update fails. There can still be a slight lag between these updates if they are processed in sequence or through separate database connections, resulting in eventual consistency.
The challenge here is that the write model becomes more complex because it must handle two updates directly, potentially slowing down the command handling process.
If one update succeeds and the other fails, you need robust error handling and rollback mechanisms.
Database polling
Database polling is an approach where the read model periodically polls the write model or the write database for changes. This involves checking for new or updated data at regular intervals (e.g., every few seconds or minutes) and updating the read-optimized views or caches accordingly.
This process introduces eventual consistency because the read model will eventually get the updated data, but there will be a delay between the write operation and when the read side reflects the changes. The tricky part of this solution is determining how often to poll the write model, as the polling interval introduces a time lag. If the interval is too long, the read model might be outdated for longer periods. On the other hand, polling too frequently could increase database load and performance overhead.
Materialized views
Materialized views are essentially snapshots of query results stored as actual tables, and they can be periodically refreshed to reflect changes in the write model. So, the read model could be derived as a materialized view in the database, where the read store automatically reflects changes made to the write store.
In this case, the database itself maintains the read side by listening for changes to the write model and updating the read model accordingly.
Materialized views depend on the underlying database technology, and it is not updated in real time but only reflects changes after a refresh. The databases update materializes views asynchronously, which results in eventual consistency rather than strong consistency.
Keep in mind that, as per the polling approach, refreshing materialized views frequently can add extra load to the database. On top of that, scaling this approach can become difficult if you have complex read models or if the underlying database is under heavy load.
Shared database
Shared database is an approach where both the write and read models use the same database, but the query layer is optimized differently for each model. The read model queries the same tables as the write model, but the queries are optimized using indexes, denormalization, or caching strategies to ensure fast reads.
As a result, this approach doesn’t involve distinct synchronization, because the read and write models are working on the same underlying data. Beware that since both models share the same database, there is less separation of concerns, which reduces the benefits of CQRS in terms of scalability and flexibility.
Database triggers
Database triggers are a replication technique where the write and read databases are synchronized through the database system itself. Triggers automatically propagate changes from the write model’s database to the read model, handling synchronization whenever data is updated.
The only advantage of this solution is that you demand the burden of updating the read model to the database without requiring explicit logic in the application.
As with the materialized views, you are heavily depending on the database technology, which could also lead to performance bottlenecks if overused and delays in the update process.
More importantly, issues in triggers can be hard to debug compared to explicit application code. That’s why you should be discouraged from following this path except for some really niche cases during your refactoring process.
Before we move on, let us look at Table 7.2 which summarizes the pros and cons of all the approaches we have discussed in this section.
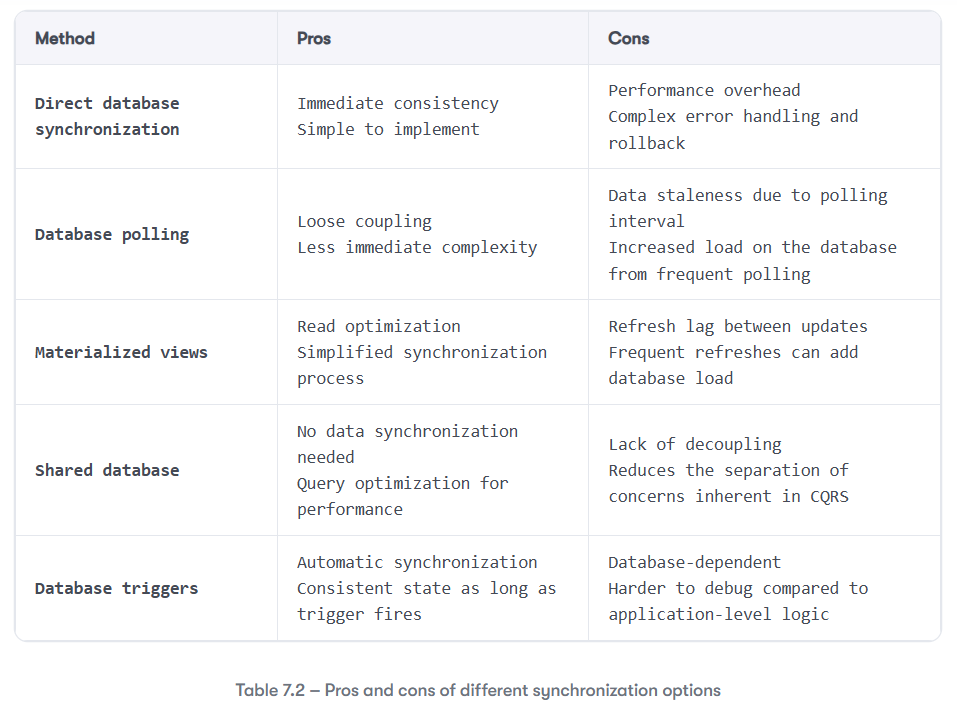
Going back to our ERP application, it is time to add the missing piece to complete the first step of our refactoring journey: the read model. Let us see how we implemented it in 02-monolith_with_cqrs of our application. To do that, let’s start with a new project in the Sales folder named BrewUp.Sales.ReadModel and in the Warehouses folder named BrewUp.Warehouses.ReadModel. Inside these projects, we will create Data Transfer Objects (DTOs) and services to query the read model.
As usual, during the refactoring process, to keep complexity at bay, you should opt for the simplest solution possible in your context. For this first step, we opted for the shared database option to not touch the database yet. You will see the strategies to better approach database refactoring in Chapter 8, Refactoring the Database.
That said, we want to create classes and services for the Sales bounded context, as shown in Figure 7.4.

Figure 7.4 – Sales read model
We also want to do this for the Warehouses bounded context, as shown in Figure 7.5.

Figure 7.5 – Warehouses read model
For starters, we created a DtoBase class in BrewUp.Shared.ReadModel and then specific DTOs named SalesOrder, SalesOrderRow, and Availability in the Dtos folders.
These classes are mirroring the ones in the domain model folder for both Sales and Warehouses.
The code is straightforward. Let’s just look at availability.cs as an example:
public class Availability : DtoBase
{
public string BeerId { get; private set; } = string.Empty;
public string BeerName { get; private set; } = string.Empty;
public Quantity Quantity { get; private set; } = new(0, string.Empty);
protected Availability()
{
}
public static Availability Create(BeerId beerId, BeerName beerName, Quantity quantity)
{
return new Availability(beerId.Value.ToString(), beerName.Value, quantity);
}
private Availability(string beerId, string beerName, Quantity quantity)
{
Id = beerId;
BeerId = beerId;
BeerName = beerName;
Quantity = quantity;
}
public BeerAvailabilityJson ToJson() => new(Id, BeerName, new Shared.CustomTypes.Availability(0, Quantity.Value, Quantity.UnitOfMeasure));
}This DTO mirrors the structure of the corresponding domain entity but is designed for the read model. It simplifies data transfer by focusing solely on the properties needed for querying, without the complexity of domain behavior.
Next, we moved the queries and services to their respective folders and changed the using clauses from BrewUp.Shared.Entities to BrewUp.Shared.ReadModel to use the new DTO classes.
This allowed us to switch from the domain model to the read model without changing the underlying service and query logic.
By doing so, we achieved a CQRS-like structure that clearly separates the read and write concerns. It is now time to move to the next step and explore how to implement event sourcing.
Capturing state changes with events
So far, you have learned about the differences between commands and domain events. Now, let’s dive deeper into the impact of choosing an event-driven aggregate solution instead of a more traditional CRUD approach.
Before starting, a quick disclaimer: as you saw earlier, using CQRS does not necessarily require using event sourcing. However, incorporating event sourcing into your design can give your application a significant boost. But it also brings extra complexity; like everything in software architecture, it is a trade-off.
The key benefit of an event-driven approach lies in how you manage state changes. In a traditional CRUD system, you are storing only the current state of the aggregate. Each time an update occurs, the new state overwrites the previous one. While this is simple, you are losing all the information on how your aggregate has arrived at its current state.
In Figure 7.6, you can observe the usual behavior of a CRUD system. A customer places an order, and at the beginning, its state is Pending with the amount the customer owes, which is €500.00.

Figure 7.6 – Example of CRUD
After the customer’s payment, the SalesOrder status is Closed and the amount the customer owes is €0.00.
In an event-sourced system, the status change would be captured as an event, as in Figure 7.7.

Figure 7.7 – Event-sourced system
Because the change of state has been captured, you not only have the same result but also the business action that you applied to obtain it.
With domain events, you shift from merely recording the last known state of the aggregate to capturing each meaningful change over time. Instead of storing just the result, you are saving the entire history of state changes through domain events. Each event is an important piece of something that happened within your domain and that composes the aggregate’s story. This makes it easier to track the lifecycle of the aggregate, understand its business decisions, and even rewind or audit changes. Now you have the movie of the aggregate, not just the picture!
Capturing a historical record through domain events makes both traceability and auditability possible, especially in systems where legal compliance, financial auditing, or business transparency is essential. Traceability refers to the ability to track the sequence of changes and understand how the system reached its current state, while auditability ensures that every change can be verified and justified for compliance or regulatory purposes.
Now that we’ve seen how capturing domain events enhances traceability and auditability, it’s important to understand how this fits into the overall system architecture.
Integrating Event Sourcing into CQRS Architecture
Event sourcing transforms how the system handles state changes, particularly when combined with the CQRS pattern. This integration ensures not only reliable data handling but also consistent, verifiable state transitions.
Figure 7.8 illustrates how CQRS architecture evolves when event sourcing is introduced. While this architectural flow was briefly discussed in Chapter 5, it’s crucial to revisit it now in the context of how domain events shape the system’s behavior and data flow.

Figure 7.8 – CQRS with event sourcing
The preceding scenario is the evolution of the one in Figure 7.3. The aggregate, when it receives a command, validates the domain rules, checks the invariants, and raises one or more domain events. These domain events are stored in an event store and are then published on an event bus. The event store becomes the source of truth of your system. That is because it stores all the domain events that have occurred, and you can rewind them to rebuild your read model or create completely new projections. If you do not remember what a projection is, do not worry—it is nothing more than a denormalized and optimized view inside the read model.
Once the domain events have been published, one or more event handlers can subscribe to them to update the projections inside the read model, create and publish integration events, send emails, and so on.
Implementing the CQRS pattern is simpler than it may look, and to make the process even more approachable, we developed our own open source library, Muflone. Our goal was to eliminate unnecessary complexity and repetitive coding often associated with CQRS. Muflone achieves this by reducing boilerplate code and streamlining implementation. If you explore Muflone, you’ll see how straightforward it is to use, and we hope it inspires you to build your own implementation without much effort. CQRS doesn’t have to be intimidating; with the right tools and mindset, it can be both practical and accessible.

Two classes in this library need to be explained in detail to help you understand the code in 03-monolith_with_cqrs_and_event_sourcing, which represents the result of the refactoring at the end of this chapter. The first is the AggregateRoot class, which, as the name suggests, represents the entity root of an aggregate. You learned about the aggregate pattern in Chapter 4, Tactical Patterns.
The following code is just a portion of the AggregateRoot class, and it focuses on the _uncommittedEvents property. This property holds the list of domain events raised by the aggregate that have yet to be persisted in an event store. Whenever something significant happens within the aggregate, you need to call the RaiseEvent method to create a domain event to apply it to the aggregate and add it to _uncommittedEvents.
The repository will use this property to persist the events. Since the domain layer is unaware of persistence concerns, when you call the Save method of the repository (explained later in this section), you pass the entire aggregate. The IRepository implementation can then either persist events for an event-sourced approach by reading _uncommittedEvents or save the whole aggregate in a traditional CRUD manner.
Here is the code just described:
public abstract class AggregateRoot : IAggregate, IEquatable<IAggregate>
{
private readonly ICollection<object> _uncommittedEvents = new LinkedList<object>();
public IDomainId Id { get; protected set; } = default!;
public int Version { get; protected set; }
void IAggregate.ApplyEvent(object @event)
{
RegisteredRoutes.Dispatch(@event);
Version++;
}
ICollection IAggregate.GetUncommittedEvents() => (ICollection)_uncommittedEvents;
void IAggregate.ClearUncommittedEvents() => _uncommittedEvents.Clear();
protected void RaiseEvent(object @event)
{
((IAggregate)this).ApplyEvent(@event);
_uncommittedEvents.Add(@event);
}
}The other important class is Repository. In the core package of the Muflone library, you can find its IRepository interface.
Here is the code:
public interface IRepository : IDisposable
{
Task<TAggregate?> GetByIdAsync<TAggregate>(IDomainId id, CancellationToken cancellationToken = default) where TAggregate : class, IAggregate;
Task<TAggregate?> GetByIdAsync<TAggregate>(IDomainId id, long version, CancellationToken cancellationToken = default) where TAggregate : class, IAggregate;
Task SaveAsync(IAggregate aggregate, Guid commitId, Action<IDictionary<string, object>> updateHeaders, CancellationToken cancellationToken = default);
Task SaveAsync(IAggregate aggregate, Guid commitId, CancellationToken cancellationToken = default);
}The IRepository interface, which forms the basis of the Repository pattern, exposes only two methods: Save and GetById, available in both synchronous and asynchronous versions. This design optimizes the write model for write operations, meaning it does not support running queries. Instead, you use GetById to load the aggregate (or rebuild it, as you will see later) from a store and Save to persist the aggregate. Nothing more.
In the following code, which is part of the EventStoreRepository implementation of IRepository in the Muflone.Eventstore.gRPC package, you can see the two methods implemented:
namespace Muflone.Eventstore.gRPC.Persistence;
public class EventStoreRepository : IRepository
{
public async Task<TAggregate?> GetByIdAsync<TAggregate>(IDomainId id, long version, CancellationToken cancellationToken = default) where TAggregate : class, IAggregate
{
if (version <= 0)
throw new InvalidOperationException("Cannot get version <= 0");
var streamName = aggregateIdToStreamName(typeof(TAggregate), id);
var aggregate = ConstructAggregate<TAggregate>();
var readResult = eventStoreClient.ReadStreamAsync(Direction.Forwards, streamName, StreamPosition.Start, maxCount: version, cancellationToken: cancellationToken);
if (await readResult.ReadState != ReadState.Ok)
throw new AggregateNotFoundException(id, typeof(TAggregate));
await foreach (var @event in readResult)
aggregate!.ApplyEvent(DeserializeEvent(@event));
if (aggregate!.Version != version && version < int.MaxValue)
throw new AggregateVersionException(id, typeof(TAggregate), aggregate.Version, version);
return aggregate;
}
private static TAggregate? ConstructAggregate<TAggregate>()
{
return (TAggregate)Activator.CreateInstance(typeof(TAggregate), true)!;
}
private static object DeserializeEvent(ResolvedEvent resolvedEvent)
{
var eventClrTypeName = JObject.Parse(Encoding.UTF8.GetString(resolvedEvent.Event.Metadata.ToArray())).Property(EventClrTypeHeader)!.Value;
return JsonConvert.DeserializeObject(Encoding.UTF8.GetString(resolvedEvent.Event.Data.ToArray()), Type.GetType(((string)eventClrTypeName)!)!)!;
}
public async Task SaveAsync(IAggregate aggregate, Guid commitId, Action<IDictionary<string, object>> updateHeaders, CancellationToken cancellationToken = default)
{
var commitHeaders = new Dictionary<string, object>
{
{ CommitIdHeader, commitId },
{ CommitDateHeader, DateTime.UtcNow},
{ AggregateClrTypeHeader, aggregate.GetType().AssemblyQualifiedName! }
};
updateHeaders(commitHeaders);
var streamName = aggregateIdToStreamName(aggregate.GetType(), aggregate.Id);
var newEvents = aggregate.GetUncommittedEvents().Cast<object>().ToList();
var eventsToSave = newEvents.Select(e => ToEventData(Uuid.NewUuid(), e, commitHeaders)).ToList();
var originalVersion = aggregate.Version - newEvents.Count;
var expectedVersion = originalVersion == 0 ? ExpectedVersion.NoStream : originalVersion - 1;
await eventStoreClient.AppendToStreamAsync(streamName, StreamState.Any, eventsToSave, cancellationToken: cancellationToken);
aggregate.ClearUncommittedEvents();
}
}The GetById method reads the events from the beginning of the events stream in the event store by calling eventStoreClient.ReadStreamAsync and then applies them to the aggregate by invoking its ApplyEvent method. In this way, it rebuilds the aggregate’s latest state.
The core of this method is an asynchronous operation that processes a stream of events. For each event, aggregate!.ApplyEvent(…) applies the event to the aggregate to rebuild its state. The DeserializeEvent(@event) method converts the event from its serialized format into an object that can be applied to the aggregate.
The Save method retrieves the domain events from the aggregate via the GetUncommittedEvents method, checks the version for optimistic locking, and appends the events to the stream using the eventStoreClient.AppendToStreamAsync method.
Now that you know how events work coupled with CQRS, we can implement events in our code base.
Adding events to our ERP
Before starting to refactor, remember that the complete code base can be found in 03-monolith_with_cqrs_and_event_sourcing of the book’s repository. We begin by working on the Sales bounded context. For starters, we refactor the SalesOrder aggregate as shown in the following code:
public class SalesOrder : AggregateRoot
{
internal SalesOrderNumber _salesOrderNumber;
internal OrderDate _orderDate;
internal CustomerId _customerId;
internal CustomerName _customerName;
internal IEnumerable<SalesOrderRow> _rows;
protected SalesOrder()
{
}
internal static SalesOrder CreateSalesOrder(SalesOrderId salesOrderId, Guid correlationId, SalesOrderNumber salesOrderNumber,
OrderDate orderDate, CustomerId customerId, CustomerName customerName, IEnumerable<SalesOrderRowDto> rows)
{
// Check SalesOrder invariants
return new SalesOrder(salesOrderId, correlationId, salesOrderNumber, orderDate, customerId, customerName, rows);
}
private SalesOrder(SalesOrderId salesOrderId, Guid correlationId, SalesOrderNumber salesOrderNumber, OrderDate orderDate,
CustomerId customerId, CustomerName customerName, IEnumerable<SalesOrderRowDto> rows)
{
RaiseEvent(new SalesOrderCreated(salesOrderId, correlationId, salesOrderNumber, orderDate, customerId, customerName, rows));
}
private void Apply(SalesOrderCreated @event)
{
Id = @event.SalesOrderId;
_salesOrderNumber = @event.SalesOrderNumber;
_orderDate = @event.OrderDate;
_customerId = @event.CustomerId;
_customerName = @event.CustomerName;
_rows = @event.Rows.MapToDomainRows();
}
}Based on what we have explained in the chapter, you will already have noticed the things we changed.
Firstly, we derived the class from Muflone’s AggregateRoot, because this class is our aggregate entry point. Then, we modified the constructor using RaiseEvent to precisely raise the SalesOrderCreated event. Finally, we defined the Apply method for the same event to update the necessary properties of the aggregate. The Apply method is called by the repository’s GetById when reading the stream and encountering an event of this type. Similarly, for other event types, the repository will invoke the corresponding Apply method within SalesOrder for each event it finds in the stream.
But now who will call the constructor? Because we are implementing CQRS with event sourcing, we need to change how things work inside our application. As you know, changes are fired by a command, so we need to create the CreateSalesOrder command and its handler. The command will be created in the Commands folder of the BrewUp.Sales.SharedKernel project while the handler will be added to the new CommandHandlers folder within the BrewUp.Sales.Domain project.
The command is straightforward:
public class CreateSalesOrder(SalesOrderId aggregateId, Guid commitId, SalesOrderNumber salesOrderNumber,
OrderDate orderDate, CustomerId customerId, CustomerName customerName,
IEnumerable<SalesOrderRowDto> rows)
: Command(aggregateId, commitId)
{
public readonly SalesOrderId SalesOrderId = aggregateId;
public readonly SalesOrderNumber SalesOrderNumber = salesOrderNumber;
public readonly OrderDate OrderDate = orderDate;
public readonly CustomerId CustomerId = customerId;
public readonly CustomerName CustomerName = customerName;
public readonly IEnumerable<SalesOrderRowDto> Rows = rows;
}The only thing to point out in the preceding code is that the CreateSalesOrder class is derived from Muflone’s Command class and if you take a look at it, you will see it is only composed of a bunch of constructors, nothing fancy.
The real work is made by the command handler that is the consumer for the CreateSalesOrder command:
public sealed class CreateSalesOrderCommandHandler : CommandHandlerAsync<CreateSalesOrder>
{
public CreateSalesOrderCommandHandler(IRepository repository, ILoggerFactory loggerFactory) : base(repository, loggerFactory)
{
}
public override async Task HandleAsync(CreateSalesOrder command, CancellationToken cancellationToken = default)
{
var aggregate = SalesOrder.CreateSalesOrder(command.SalesOrderId, command.MessageId, command.SalesOrderNumber,
command.OrderDate, command.CustomerId, command.CustomerName, command.Rows);
await Repository.SaveAsync(aggregate, Guid.NewGuid());
}
}What matters in the preceding code is HandleAsync. It is this method that calls the constructor of SalesOrder passing by its factory.
Inside the constructor, the event is raised and added to the UncommittedEvents list that will be persisted by the call to Repository.SaveAsync.

Now that we have completed the handling of the command, it is time to move to the other side of the aggregate. We need to handle the events.
We know that the aggregate constructor, upon verifying the invariants, will raise an event called SalesOrderCreated (remember the past tense because something has happened). We then need to create the event in the Events folder of BrewUp.Sales.SharedKernel and its handler in the EventHandlers folder of the BrewUp.Sales.ReadModel project.
The code for the event is as follows:
public sealed class SalesOrderCreated(SalesOrderId aggregateId, Guid commitId, SalesOrderNumber salesOrderNumber,
OrderDate orderDate, CustomerId customerId, CustomerName customerName,
IEnumerable<SalesOrderRowDto> rows) : DomainEvent(aggregateId, commitId)
{
public readonly SalesOrderId SalesOrderId = aggregateId;
public readonly SalesOrderNumber SalesOrderNumber = salesOrderNumber;
public readonly OrderDate OrderDate = orderDate;
public readonly CustomerId CustomerId = customerId;
public readonly CustomerName CustomerName = customerName;
public readonly IEnumerable<SalesOrderRowDto> Rows = rows;
}As you can see, the SalesOrderCreated event, just like a command, is a simple message that carries information. However, as an event that remains within the bounded context, it is derived from the DomainEvent class rather than the IntegrationEvent class.
As you can already imagine, we need to create its respective handler, which is one of what could be many subscribers for the event:
public sealed class SalesOrderCreatedEventHandlerAsync(ILoggerFactory loggerFactory, ISalesOrderService salesOrderService)
: DomainEventHandlerAsync<SalesOrderCreated>(loggerFactory)
{
public override async Task HandleAsync(SalesOrderCreated @event, CancellationToken cancellationToken = new())
{
try
{
await salesOrderService.CreateSalesOrderAsync(@event.SalesOrderId, @event.SalesOrderNumber, @event.CustomerId,
@event.CustomerName, @event.OrderDate, @event.Rows, cancellationToken);
}
catch (Exception ex)
{
Logger.LogError(ex, "Error handling sales order created event");
throw;
}
}
}Again, everything is relatively simple; the handler reacts to the event and passes the information to our service, which will update the projection with the new SalesOrder.
The last piece of the puzzle is how to deliver messages throughout the system. We need to eliminate the mediator project that we no longer need and, in the infrastructure project, add a service bus that will replace the mediator in communicating with the various parts of the system.
As explained earlier, the service bus will be responsible for receiving and delivering messages to the command and event handlers. We will not delve into the code because the Mulfone.Trasport.RabbitMQ package will solve all the implementation details of the RabbitMQ service bus (this is the service bus we chose for our application) and it is not in the scope of this book. Anyway, all the source code is publicly available if you want to understand the inner workings of this package.

An event-sourced system offers many advantages other than those you discovered until now. For example, one of the most challenging aspects of designing a system is accurately reflecting the business intent within your solution. Domain events are powerful because they mirror actual business actions. Rather than only storing the final state of an aggregate, events capture the sequence of actions that lead to that state. This gives you a deeper understanding of the business processes at play, providing critical insights into how and why specific outcomes were reached. With this visibility, you are able to make more informed decisions, as your system isn’t just tracking data, it is also aligned with the intent and reasoning behind each change.
To learn how to test the event-driven modular monolith, implement event-driven communication, structure modular monoliths with CQRS, and apply event sourcing for scalable state management—check out Domain-Driven Refactoring by Alessandro Colla and Alberto Acerbis, available from Packt.

Here is what some readers have said:


 | A guest post by
|
 | A guest post by
|