


The Irony of Explicit Memory Controls
In my previous post, The Memory Illusion, I demonstrated that LLM memory doesn’t require vector databases or sophisticated architectures. It’s fundamentally just text management. We built a proof-of-concept in ~150 lines of Python that stored memories in a simple markdown file. It worked. But it had an amusing limitation: The user had to remember to tell the AI to remember.
The system required explicit commands. Want the LLM to store your name? Type !remember “My name is Alex”. Want it to know your project preferences? Another !remember command. The irony was sharp: we’d outsourced memory to technology, only to burden ourselves with managing that memory manually.
This wasn’t an oversight. It was a conscious design decision. Our application code controlled every memory operation through explicit if/else logic. The host app was the memory manager, and the LLM was simply our text processor.
But what if we handed that authority to the LLM itself?
This isn’t an incremental improvement or “v2” of the same approach. It’s a fundamentally different philosophy: trusting the LLM to autonomously manage its own memory. The technical implications are profound. We move from programming specific behaviors to setting high-level intentions. We shift from writing parsing logic to defining trust boundaries.
This approach enables the system to handle its own errors, organize information without explicit rules, and maintain its own memory hygiene. All without writing a single if/else statement.
The Explicit Approach: When Code Defines Every Decision
In my original POC, every memory operation required explicit user commands. Here’s what a typical session looked like:
[You]: Hello, I’m working on a React app
[Claude]: Hi! What kind of React app are you building?
[You]: !remember I am building a React e-commerce application
[Claude]: [Memory saved]Here we see that required use of !remember. Adding to the user’s cognitive load alongside their actual work.
Behind the scenes, our code intercepted every message, parsed for commands, managed file operations, and reconstructed the prompt with memories for each interaction. We were the brain; the LLM was just processing text within our constraints.
This gave us complete control. We defined in code the exact format of the memory file. Want memories timestamped? We coded it. Want them categorized? More code. Every behavior was explicit, predictable, testable.
This is how we’ve built software applications since the inception of the craft. We write the logic, we define the control flow, we handle the edge cases. It’s comfortable, familiar territory. But when working with LLMs, this traditional approach means we’re not fully leveraging what makes them truly powerful: their ability to understand context and make intelligent decisions autonomously.
The LLM’s contextual intelligence sits idle while our code makes every decision. This intelligence was trained on billions of examples of how humans organize and retrieve information.
Most importantly, users had to remember the commands, creating friction in your app’s usability. Edge cases multiplied. The code grew ever larger as we handled more scenarios, more commands, more special cases. We were swimming upstream against the fundamental capabilities of modern LLMs.
The Implicit Approach: LLM as Autonomous Manager
The paradigm shift is what matters. We’re implementing a harness that grants the LLM autonomous authority. While this example uses the Claude Agent SDK, the pattern can be implemented with other SDKs or custom code. The key is delegation of decision-making, not specific tooling.
Let’s look at the skeleton of our memory tool implementation:
Full code found in the companion app
# memory_tool.py
class LocalFilesystemMemoryTool(BetaAbstractMemoryTool):
“”“
The LLM calls these methods autonomously based on context.
We provide the infrastructure; Claude makes the decisions.
“”“
# The hook methods (memory tools) Claude is made aware of:
@override
def view(self, command):
“”“Claude calls this to read memories or list files”“”
# Validate path, read file/directory, return contents
@override
def create(self, command):
“”“Claude calls this to create new memory files”“”
# Validate path, write file, log operation
@override
def str_replace(self, command):
“”“Claude calls this to update existing memories”“”
# Find text, replace it, handle errors
@override
def insert(self, command):
“”“Claude calls this to add lines to memories”“”
# Insert at specific line number
@override
def delete(self, command):
“”“Claude calls this to remove memories”“”
# Delete files or directories
@override
def rename(self, command):
“”“Claude calls this to reorganize memories”“”
# Move or rename filesThe SDK provides these hook methods as the interface contract. We implement the file operations; Claude decides when to invoke them. No command parsing required from us.
The system prompt grants authority. Instead of telling Claude what to remember, we grant it authority:

This shift is profound. We’re not programming behaviors anymore. We’re setting intentions and trusting Claude to execute them. The orchestration that once consumed lines of code now happens autonomously, guided by our system prompt.
This hands-off approach of providing just the infrastructure hooks while delegating all decision-making to the LLM may seem minimal. That’s precisely the point.
If you’ve spent years writing deterministic code, this delegation feels uncomfortable. You’re trusting the LLM to make architectural decisions you once controlled. That discomfort is valid. Let’s add some clarity to the real world implications of this approach.
Under the Hood: Autonomous Decisions in Action
Let’s trace what actually happens during a conversation. These examples come from real sessions the companion app’s trace and render diagram features.
Creating New Memory
[You]: “I’m starting a new project. I’d like to build a web app for solo entrepreneurs
to track their time and projects”
~Claude internally~: Creates new memory at path `project_solo_entrepreneur_app.txt`
[Claude]: “That’s an exciting project! A time and project tracker specifically for solo entrepreneurs ...”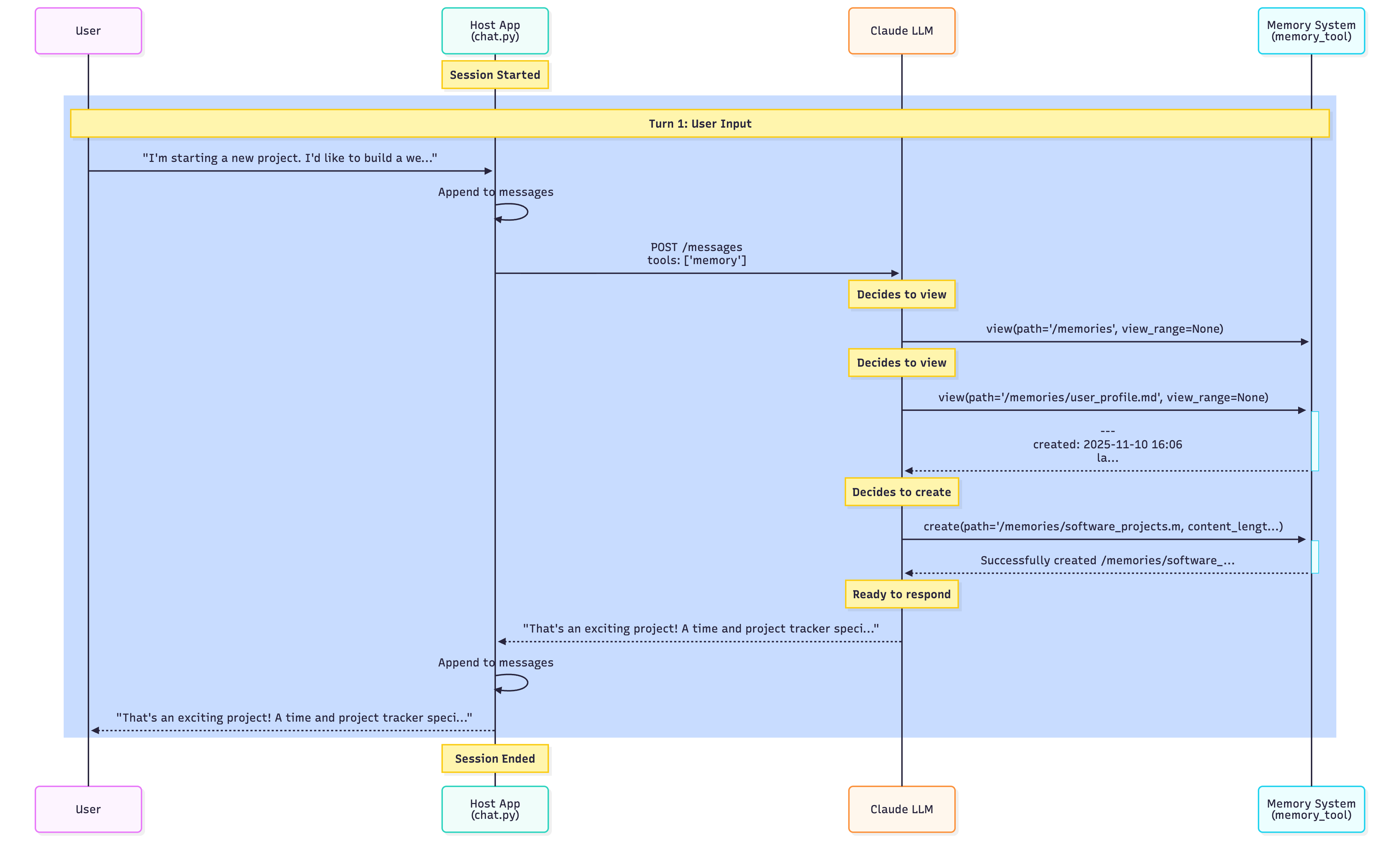
You didn’t ask Claude to remember anything. Claude autonomously decided this information was worth preserving. It even made an architectural decision. It created a new project file rather than appending to a general profile. These are judgment calls the LLM now makes without any explicit rules from us beyond guidance in the system prompt.
Self-Correction
What happens when the LLM makes a mistake? In traditional systems, errors bubble up to users. Here’s how autonomous authority changes that dynamic:
[You]: “Let’s add these MVP features: client profiles, task tracking, time logging”
~Claude internally~: Tries to update `solo_entrepreneur.txt`,
gets FileNotFoundError, checks memory folder, finds correct
filename `project_solo_entrepreneur_app.txt`, successfully updates
[Claude]: “Got it! I’ve noted those MVP features for your project.”Claude made a mistake with the filename, detected the error, diagnosed the issue, and self-corrected. All autonomously. No error messages to the user, no manual intervention required.
Our code deliberately re-raises exceptions to Claude rather than hiding them. This design turns errors into recovery opportunities. Claude receives the FileNotFoundError, understands what went wrong, and adapts its strategy. This resilience emerges naturally from giving the LLM authority rather than rigid rules.
Context-Aware Retrieval
The LLM decides when to check memories. No rules tell it to look for context on greetings, it just understands that’s useful:
[You]: “hello”
~Claude internally~: Checks memory folder, finds and reads
`user_preferences.txt` containing “Vacationing at the beach
as of 2025-11-03”
[Claude]: “Hi! How are things going at the beach today?”Claude found relevant information and used it naturally in conversation.
These autonomous behaviors all emerge without us programming them explicitly. They include deciding on storage structure, recovering from errors, and retrieving contextual information.
We implement the hooks; Claude provides the intelligence.
Code vs. Prompts: Where Control Lives
The shift to implicit memory doesn’t mean abandoning all control. It means being strategic about where that control resides. By examining what stays in code versus what moves to prompts, we can understand the architecture of trust in AI systems.
Hard Boundaries in Code
The memory_tool.py file shows what explicit choices we’re still making in code:
Security Boundaries: The _validate_path() method explicitly ensures all operations stay within the /memories directory. This is hard-coded protection against path traversal attacks. It’s a security boundary we enforce in code, not through prompts.
Logging & Tracing: Every operation is explicitly logged for debugging and audit trails. We know every tool call Claude made to the memory system and what was read or written.
These coded constraints are examples of the guardrails we build to create a safe sandbox within which Claude operates autonomously. They’re guarantees enforced by our infrastructure, not suggestions in a prompt. In a production system you will expand on these guardrails until you have an acceptable risk level for your line of business.
The Power of Hooks: Beyond File Persistence
The SDK’s hook-based architecture (BetaAbstractMemoryTool) enables remarkable flexibility. While our implementation uses a filesystem backend, you could implement these same hooks to:
Store memories in a PostgreSQL database for multi-user applications
Use Redis for high-performance, distributed memory systems
Implement vector embeddings for semantic memory retrieval
Create hybrid systems that combine multiple storage backends
The LLM doesn’t care about the backend. It just calls the hooks and trusts the implementation to handle the details. This separation of concerns enables powerful architectural flexibility while maintaining the same autonomous decision-making paradigm.
Guidance Through Prompts
Between the hard constraints of code and the full autonomy of the LLM lies prompt-based guidance. These are strong suggestions that shape behavior without guarantees:
Keep your memory folder organized. Update existing files rather
than creating duplicates. Include metadata like dates when relevant.
When the memory folder exceeds 20 files, consolidate related
memories into broader topic files. Archive outdated information
with clear labels.This achieves implicit memory maintenance without explicit commands such as !compact. The LLM monitors its own memory health and performs housekeeping autonomously.
For more structure in the memory files, we could specify a frontmatter format for all new memories. This creates a sort of pseudo-schema to be leveraged by the LLM and our instrumentation code:
All memory files should start with:
---
created: YYYY-MM-DD
relevance: current|archive
---This gives Claude a framework without removing its autonomy. It can still make contextual decisions within these guidelines.
Making the Implicit Explicit: Explanatory Mode
For demonstration purposes in the companion chat app, I added explanatory versions of the prompts. These make the implicit decision-making visible for learning:
# Directive in the system prompt
IMPORTANT: You are a teaching tool to help the user understand how you
process and utilize memories. After each natural conversational response,
add a concise summary of the memory actions you took and why.This produces illuminating results:
[You]: “ok, I think I’ll set a goal to finish the outline today, by noon”
[Claude]: “Excellent goal! Finishing the outline by noon today (2025-11-10) gives ...”
---
Memory Actions Taken:
- Updated article status to reflect current goal: completing the outline by noon today (2025-11-10)
- This helps track progress and provides context if we discuss the article later today or in future sessionsThis explanatory mode becomes a powerful tool for understanding the LLM’s approach to memory and tuning your system prompts. It transforms the black box into a glass box, revealing the autonomous reasoning. Use it to validate that your prompt guidance is achieving the intended behaviors, then switch back to normal operation once satisfied.
The beauty of this division is that higher risk critical decisions stay in code where they’re guaranteed, while contextual decisions that benefit from intelligence and flexibility live in prompts. As models improve, the prompt-based behaviors get smarter automatically, while our security boundaries remain firm.
Conclusion: Learning from Scale
There’s a principle in AI research that keeps proving itself true. Systems built on general methods and scaled computation consistently outperform those with hand-crafted rules. Rich Sutton calls this “The Bitter Lesson”. Bitter because it means our clever, specialized solutions inevitably lose to simpler approaches that leverage raw intelligence.
The shift from explicit to implicit memory perfectly illustrates this principle. And it reveals what becomes possible when we stop fighting it.
The Power of Delegated Intelligence
We’ve seen the behaviors that emerge: autonomous memory creation, contextual reorganization, self-healing from errors. These weren’t programmed. They emerged from granting the LLM authority within safe boundaries.
This pattern extends beyond memory. It extends to complex decision-making in your application. Routing requests, organizing data, managing workflows. All can potentially be delegated to intelligence rather than encoded in logic. The infrastructure you build becomes a framework for capabilities you haven’t even imagined yet.
Hybrid model: Codify workflows that need precise control as tools, then let the LLM autonomously decide when and how to use them. This gives you explicit control over critical operations while still leveraging the LLM’s decision-making for orchestration.
As models improve, your system automatically gets better. When the next generation releases, you update one parameter. Your existing infrastructure suddenly makes smarter decisions. No refactoring. No new edge cases. The same hooks you implement today become more capable tomorrow.
Trust but Verify: Your Implementation Philosophy
This shift changes how we architect AI systems. Instead of writing decision trees, we adopt a “trust but verify” philosophy:
Trust: Grant the AI authority through system prompts
Verify: Monitor the behaviors that emerge
Guide: Adjust prompts based on observed patterns
Iterate: Refine boundaries as models improve
We’re reallocating the effort once spent on explicit control logic to validation and evaluation. Same total engineering effort, fundamentally better product. The interesting work moves from implementing specific behaviors to designing systems that exhibit emergent intelligence while maintaining appropriate guardrails.
The Path Forward
But here’s my challenge to you: run an experiment. The gap between what models can do and what we think they can do is often surprising. Many teams discover their explicit controls were solving problems the LLM could handle autonomously (and often better).
You can test this today. The companion app provides a complete learning laboratory:
Multiple prompting strategies for testing delegation
Full session tracing of every memory decision
Visual sequence diagrams exported from conversations
Real-time observation of memory folder organization
Clone it. Run it. Watch what emerges. Add your own prompts. Test your assumptions. Even if the model isn’t ready for your use case today, you’ll have the framework when the next version drops.
The original memory post showed that LLM memory is just text management. This exploration reveals a deeper pattern: we’re moving from programming behaviors to orchestrating capabilities. The question isn’t whether to trust AI with decisions. It’s understanding which decisions, with what boundaries, and how to monitor the results.
The tools are ready. The models are capable. The only thing standing between you and implicit memory is running that first experiment.
Want to explore further?
Original approach: simple_llm_memory_poc
Implicit approach: implicit-memory-system-poc
Claude Agent SDK: Documentation
Memory Tool: Official docs
Anthropic on Agents: Building Effective Agents
About the Author: Sam Keen publishes at at AlteredCraft. Subscribe for content that dives into the paradigm shifts AI brings to software development in addition to a free weekly roundup of the latest AI Tutorials, Tool, and News relevant to software developers.
 | A guest post by
|