

From Prototype to Production: Why AI Systems Need Architecture Discipline
How architecture makes model- and data-driven systems production-ready

The GenAI Divide: STATE OF AI IN BUSINESS 2025 study by MIT NANDA surveyed several hundred executives on AI initiatives and found that only 5% of AI projects demonstrated lasting value. AI initiatives fail to make it to production because teams don’t define how the AI will deliver value or account for the complex realities of a production environment. In this article, we discuss specific gates and actions that, if followed, will mitigate the risk of a failed prototype-to-production deployment. A very short exemplar or mini-case study is included.
Why call out AI systems? Unlike traditional software, AI systems are model- and data-driven: behavior depends on training data, live inputs, and evaluation metrics. Architecture is how we make that behavior predictable and operable in production.
Why architecture work matters
Architecture makes prototypes survivable in production by forcing end-to-end thinking about data reality, key non-functional constraints, stakeholder trust, and the documentation that turns design into testable behavior.
Data reality: The key driver in any AI system is the quality of the data used for training and inference. Data engineering is often not done well or not done with a large enough aperture to appreciate the full end-to-end system. For example: does the prototype assume well-formatted or highly structured data that is not possible in production? Did the prototype suppose that data into the system was ordered but, in a production environment, that is not the case? Was the system overly reliant on a technology that cannot scale to expected production data rates? And so on.
Partitioning and organization: Software architecture involves design decisions about partitioning and organization. An analysis of the software components of the prototype can identify where choke points may occur, how interfaces into and out of the prototype were handled, and where a component may require more design work in a production environment.
Non-functional requirements: A robust architecture captures and understands the key non-functional requirements at play in the production environment. For example, will the new AI functionality impact availability requirements that, if not met, would result in a critical error? Does the new model with higher production data rates impact performance requirements that have cascading effects?
Trust tolerance: Robust architecting should illuminate the trust tolerance and decision making of key stakeholders. For example, does a single off-nominal inference or decision result in a loss of confidence or outright hostility to the new AI functionality? As part of a conceptual design, guard rails or off ramps can be put into the design so there is a sort of “no-harm” guarantee that may cause consternation but not a loss of confidence.
Documentation to test: The documentation of a conceptual design can aid in defining and illuminating test cases and scenarios that the prototype must satisfy in a production environment.
A fair criticism—and the response
It’s reasonable to say that architecting adds “document-centric” work that slows delivery. But the MIT statistic exists for a reason: no amount of heroic coding fixes a flawed architecture. Water doesn’t flow uphill; a bad architecture produces a bad system. Agile methods work best when a stable architectural frame guides rapid prototyping, integration, and demos. Productive engineering isn’t only writing code—it’s also designing systems that can survive production.
Architecting is critical in guiding engineering decisions and priorities. This is done by laying out the conceptual design of the end system. One of the first drivers of architecture is to have a solid conceptual design that informs prototyping. That same design later anchors the pass/fail criteria that we can categorize into gates.
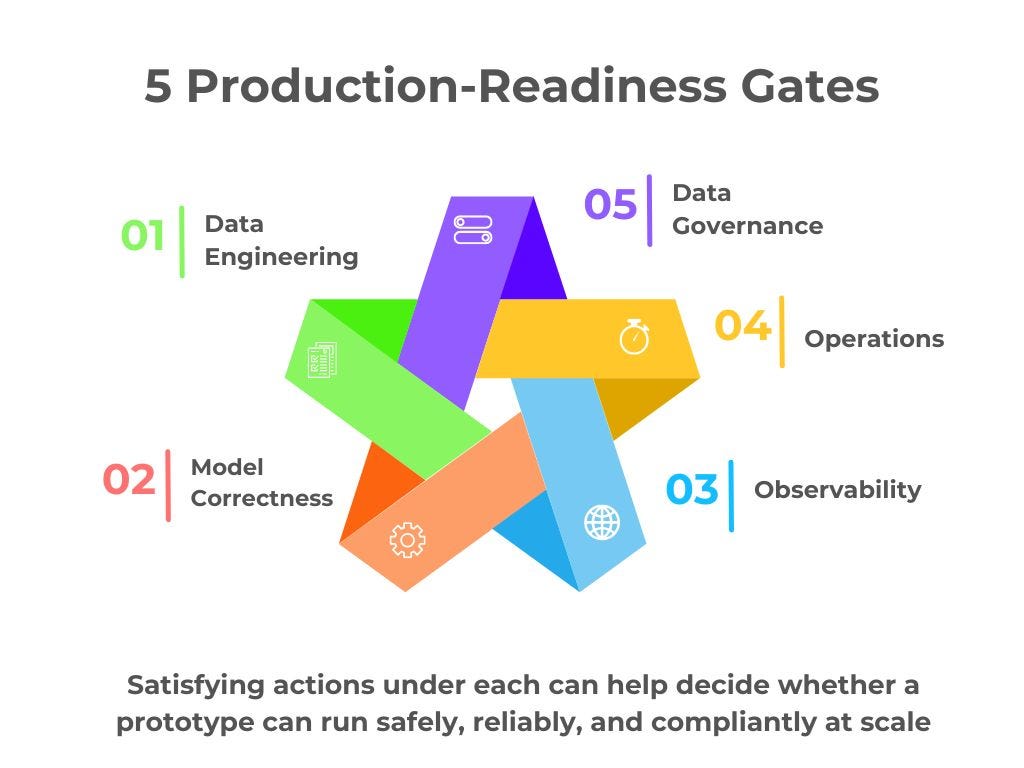
Five production-readiness gates (with actions)
There are five gates or decision buckets—pass/fail outcomes we must clear before go-live.
Note: the following actions are not exhaustive.
1) Data Engineering (AI inputs and contracts)
Analysis: Confirm that production inputs and interfaces match what the model expects—data rates, formats, fields, identifiers, consistency, and summary statistics.
Ingest testing: Exercise the pipeline with current production data and verify ingest correctness and throughput.
Resilience checks: Prove the prototype tolerates malformed records, off-nominal flows, and misformatted streams without cascading failures.
2) Model Correctness (does the model still earn its keep?)
Ongoing relevance: Verify the model still solves a real user problem; retire it if it no longer does.
Performance on live data: Re-evaluate with current production samples; confirm metrics such as AUC, accuracy, and false positive rate meet or exceed targets.
Execution time: Show end-to-end model latency remains within bounds required by downstream consumers and users.
3) Observability (for data pipelines and model behavior)
Data flow telemetry: Logging and monitors for inputs, transformations, and handoffs.
Model execution telemetry: Traces, metrics, and logs for inference paths and failure modes.
Acceptance bounds: Document thresholds, alert rules, and expected distributions for observability metrics.
4) Operations (release and recovery for AI pipelines)
Canaries: Implement canary or shadow releases to surface pipeline issues before full rollout.
Time budgets: Define and monitor time bounds for the full pipeline and each critical stage.
Update paths: Document steps for model refresh, rollback, and disentanglement from production if needed.
5) Data Governance (quality, compliance, ethics)
Quality audit: Run a data quality review on the latest production datasets.
Compliance docs: Prepare artifacts to satisfy regulatory, security, and privacy requirements.
Ethical filters: Enforce policy-aligned filtering and access controls.
In addition to these gates, the key non-functional requirements for the system need to be monitored, with action plans to ensure they are met—for example, time budgets across the system via specialized logging and canary deployments.
The gates define what must be true to go live; let us go a step further and look at the rubric that translates the actions into concrete checks and artifacts that prove each gate is passed.
Rubric for pre-deployment checks
Here is a rubric you can use as a go/no-go gate: confirm business relevance, data contracts, operational readiness (including rollback), on-call coverage and monitoring, and model quality against explicit SLOs before promoting any prototype to production.
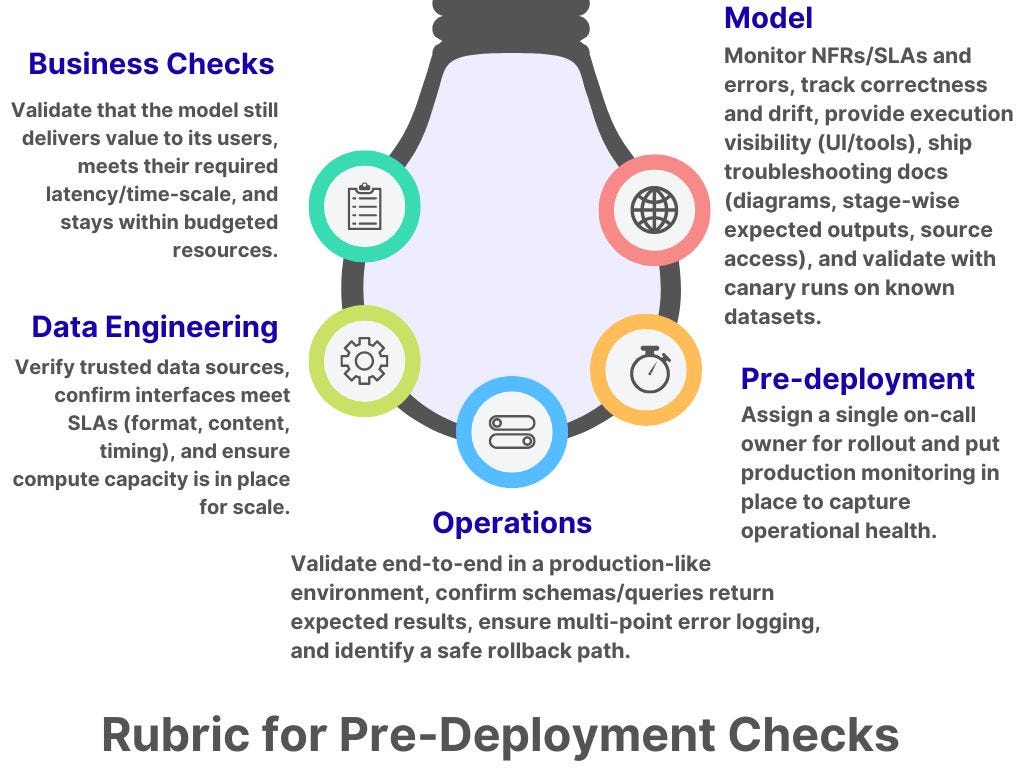
This rubric is the evidence and checks that prove each gate is passed and that you can go live.
Business Checks
Is the model output still relevant to intended users?
Is the prototype operating at time scales relevant to users?
Is the prototype still within budget and resource limits?
Data Engineering
Verify data sources.
Verify interfaces still meet service-level agreements (format, content, time budgets).
Confirm computational resources for scale are in place.
Operations
Verify the prototype in a pre-production environment or a simulation that mimics true production.
Confirm datastore schemas and queries execute correctly and produce expected results.
Ensure error logging exists at multiple points with sufficient detail for troubleshooting.
Identify a rollback procedure to take the model offline if needed.
Pre-deployment
Identify a developer or staff resource to support rollout and address issues promptly.
Ensure monitoring is in place to capture operations.
Model
Monitor non-functional requirements, SLAs, and errors.
Track correctness metrics (AUC, accuracy) and model drift.
Provide a user interface (or tools) to visualize execution.
Supply guides/documentation for troubleshooting, architecture diagrams, expected outputs at each stage, and accessible source code.
Use canaries with injected known datasets for monitoring.
Mini case study
To understand how the 5 gates and the rubric work in cohesion, let us take the example of a new application that recommends technical articles to an engineering audience. Before launch, the team decides to apply actions under each of the 5 gates and the Pre-deployment checks reveal the following:
Data & Schema
Since training began, an extra tag field was added; the date format also changed, breaking metadata parsing.
The datastore schema drifted: a key field changed, requiring interface updates.
Model Correctness: On current production data, AUC dropped below training thresholds; investigation showed an over-represented training subset.
Observability: Logging failed; output and processed-file logs couldn’t be written due to permission issues.
Operations & Release: The team planned to launch at peak traffic with no rollback procedure.
Governance: A compliance check found personal information was being collected and shouldn’t have been.
As a result, a failed release is prevented.
For AI systems, some architecting during prototyping helps cross the chasm from an impressive demonstration to a production system that delivers true value and positive business outcomes.
If you found this article insightful, Richard D Avila and Imran Ahmad’s forthcoming book, Architecting AI Software Systems extends the same ideas with a structured approach to integrating AI into traditional architectures—covering how inference and decision-making shape design, using architectural models to ensure cohesion, mitigating risks like underperformance and cost overruns, and applying patterns and heuristics for scalable, high-performance systems—anchored by real-world case studies, hands-on exercises, and a complete example of an AI-enabled system for architects, engineering leaders, and AI/ML practitioners.

About the Author:
Richard D Avila is a software and systems architect with over two decades of industry experience building complex software systems. He has architected and held leadership roles for building a wide array of software systems from complex simulations, autonomy and data analytic systems. He is also a principal investigator for AI topics. He has published in referred journals and industry publications on command-and-control theory, assurance architectures, multi-agent modeling, and machine learning. He was the first expert instructor on data analytics at University of Maryland Baltimore County – Training Centers. Before working as a software and systems architect, he served in the US Navy as a submarine officer.
 | A guest post by
|