

Deep Engineering #19: Sean Alvarez & Ajay Chankramath on Platform vs. SRE—Seven Guiding Principles
Where should orgs draw the line between Platform Engineering and SRE?




Join us at RustLab 2025 — Florence, Nov 2–4

The international conference for Rust developers returns to The Social Hub Belfiore, Florence with two days of talks plus a workshop day, a newly published schedule, and a sustainability focus via RustLab for the Planet. Expect deep, practical sessions from industry speakers and plenty of hallway time with the Rust community.
✍️From the editor’s desk,
Welcome to the nineteenth issue of Deep Engineering.
The 2025 DORA State of AI-assisted Software Development study report shows AI is now near-universal (≈95% adoption): throughput is rising, but delivery remains unstable; meanwhile, 90% of organizations report adopting platform engineering. With AI-driven speed and platforms everywhere, the practical question is who owns flow and who owns reliability. Where to draw the line between Platform Engineering and SRE?
For this issue, my colleagues
and sat down with Sean P Alvarez and Ajay Chankramath to distill seven principles that separate Platform (removing developer friction by building an internal product) from SRE (safeguarding runtime reliability)—and how clear ownership closes the speed-versus-stability gap.Alvarez is CTO for Brillio’s Life Sciences business, leading engineering and advising on cloud and platform modernization. Chankramath is Cofounder and CEO of Platformetrics, a Platform Engineering Ambassador and Team Topologies advocate. They are co-authoring The Platform Engineer’s Handbook (Packt, 2026).
In this issue:
Feature Article: SRE and Platform Engineering: Clarified Using Guiding Principles by Sushma Reddy with Sean P Alvarez and Ajay Chankramath
Packt × Humble: Ultimate Programming Languages Bundle

Level up your stack with 35 expert eBooks across Python, Rust, Go, C#, TypeScript, C++, Swift, Kotlin, Haskell, and more—cookbooks, patterns, and hands-on guides from beginner to advanced. It’s pay-what-you-want, DRM-free (PDF/ePub), and supports The Global FoodBanking Network.
SRE and Platform Engineering: Clarified Using Guiding Principles
-by Sushma Reddy with Sean P Alvarez and Ajay Chankramath
This feature is Part 1 of our conversation with Sean P Alvarez and Ajay Chankramath; we’ll publish the second installment in a forthcoming issue.
According to Atlassian’s The State of Developer Experience in 2025, 68% of developers save 10+ hours a week with AI, yet 50% still lose 10+ hours to non-coding work. This is the gap modern orgs need to address now. And to do this it is important first to identify what Platform Engineers own vs. Site Reliability Engineers. Because a clear split can help eliminate ownership confusion, speed up delivery, reduce incidents, and make metrics and investment decisions straightforward.
Sean Alvarez and Ajay Chankramath frame this distinction not just in terms of tasks, but through seven guiding principles of modern platform practice. These are not software design principles in the traditional sense, but rather practical principles for organizing work, measuring outcomes, and aligning teams.
If you are a Director or Head of Platform/SRE, a Staff+ engineer moving into platform ownership, or an engineering/product leader accountable for delivery and reliability, Alvarez and Chankramath’s seven guiding principles will help you draw clean boundaries, select the right metrics, and make near-term ownership decisions that reduce developer friction without compromising runtime reliability.
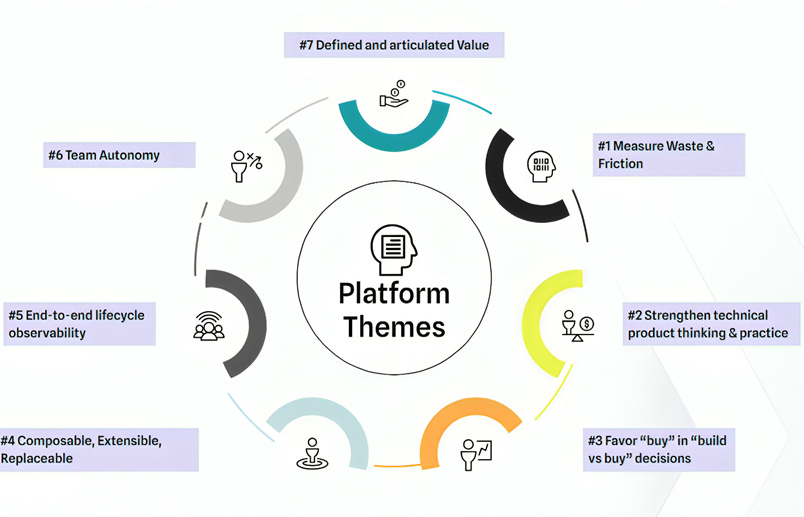
The 7 Principles of Modern Platform Practice
Measure the Friction, Track the Value: The first principle is about being data-driven. Platform engineering begins by identifying developer pain points — long wait times for environments, manual release steps, or compliance bottlenecks — and then measuring how changes reduce that friction. For example, introducing a self-service pipeline can cut provisioning from weeks to minutes.
For SREs, measurement means tracking reliability targets (SLOs, MTTR, change failure rates). The difference is in the object of measurement: SREs measure system uptime for end-users, while platform engineers measure developer experience and throughput for internal teams.
Treat the Platform as a Product: Chankramath calls this the biggest differentiator of platform engineering.
“This is not about building some automation or some software, but this is about building that as a product. Just like you have external products, your platform engineering activities… are also products.”
He explains that a platform is not just automation scripts or a Kubernetes cluster. It is a product with internal developers as its customers. That means assigning product ownership, gathering feedback, and iterating on features.
SREs, by contrast, don’t build products — they safeguard services. Their “product” is reliability itself. This principle marks a clear line: platform engineers build reusable products for developers; SREs ensure services meet agreed reliability levels.
Build vs. Buy Deliberately: Another principle is to avoid reinventing the wheel. Platform engineers should make conscious decisions about what to build in-house and what to adopt from vendors.
“A lot of people are immediately going to think, well, Kubernetes, right? But it’s certainly not all they do… In some cases, they may not even use a Kubernetes cluster. They’re automating the ability for developers to quickly spin up new projects and deployment pipelines,” explains Alvarez.
Cloud providers already offer managed services, CI/CD tooling, and observability platforms. The platform team’s role is to orchestrate and integrate, not replicate.
SREs may influence these choices by highlighting reliability requirements, but the responsibility for tooling strategy lies with platform engineers. This separation prevents both roles from duplicating effort.
Composable, Replaceable Architecture: Platform engineering must avoid brittle, locked-in solutions.
“With the advent of public cloud over the past 10–15 years… we are seeing a lot of these services coming out of the CSPs themselves, which has made it far easier for smaller teams to adopt and make sure it works within the ecosystem.”
Chankramath highlights the need for plug-and-play, cloud-integrated architectures that can evolve. Systems should be composable and replaceable, allowing components (pipelines, monitoring tools, identity systems) to evolve over time. This keeps the platform resilient as technology changes.
SREs consume these components but don’t design the platform’s architecture. Their focus is resilience at runtime: graceful degradation, failover, and scaling. Once again, the principle clarifies scope — platform teams build flexible foundations, SREs ensure production systems stay healthy on top of them.
Observability Across the Pipeline: Both SRE and Platform Engineering rely on observability, but they apply it differently.
SREs need deep visibility into production systems: logs, traces, error rates, latency.
Platform engineers embed observability into the platform itself, ensuring every service gets baseline monitoring out-of-the-box.
This principle shows how SREs and PE complement one another: platform teams standardize observability, SREs use it to uphold reliability.
Enable Self-Service and Autonomy:
“Once I put this out there and someone uses it, if they have to contact me or put in a ticket to make that happen, I need to improve it… No one should have to contact me about it on a day-to-day basis,” says Alvarez.
He emphasizes that if developers must raise tickets to use a platform feature, the platform has failed. Self-service is core: pipelines, infrastructure, and observability should all be consumable without waiting for the platform team.
For SREs, autonomy matters in a different way. They want developers to follow paved roads so they don’t end up firefighting brittle, one-off deployments. By enabling autonomy, platform engineers actually free SREs from unnecessary toil, allowing them to focus on higher-level reliability work.
Articulate and Demonstrate Value: Finally, a platform must prove its worth.
“Build your communication skills, build your soft skills… Sometimes far more important than your technical skills. Because you’re not just selling solutions — you are understanding, communicating, and building relationships to take the organization to the next level, ” says Chankramath.
Success is measured in DORA or SPACE metrics: faster deployment frequency, shorter lead times, fewer failures, and improved developer satisfaction.
SREs measure value differently — through error budgets, SLA compliance, and reduced downtime. Both disciplines need metrics, but their audiences differ: platform engineers demonstrate ROI to internal developers and leadership, while SREs demonstrate it to end-users and customers
Taken together, these principles establish who builds and standardizes the internal product (Platform) and who enforces reliability in production (SRE), forming the basis for joint work on observability, incident response, and change management.
The Evolving Partnership
Alvarez and Chankramath are also optimistic about how the SRE role is evolving in ways that strengthen collaboration with platform engineering. The model is straightforward: platform engineers provide the tools, SREs use those tools to keep systems reliable.
We can already see evidence of this shift in the industry. According to Hasith Kalpage, CISO and Platform Engineering Director at Outshift by Cisco, the group moved from an SRE-led model to Platform Engineering to increase predictability, reduce burnout, and improve developer self-service.
Microsoft Learn guidance describes platform-engineering governance as defining and implementing security, compliance, and remediation policies; monitoring threats; and managing access controls across the SDLC—i.e., the “paved roads” that regulated organizations rely on—while operational reliability remains a production concern for SRE. For teams that implement governance as code, Microsoft separately documents Azure Policy as Code workflows.
Both roles are also adapting to AI. Recently, in the context of product capability, Deepak Kallakuri, Group Product Manager, GCP Foundation Services and Mark Church, Product Manager, GCP Foundation Services described Gemini Cloud Assist Investigations, an AI-driven RCA agent that analyzes logs, configs, and metrics to propose probable causes and fixes. Datadog’s DASH 2025 automation features also indicate the current direction of incident assistance, and Splunk’s Global State of Security 2025 links shared observability data to faster detection and remediation.
However, Automation and AI assistants have not eliminated the roles — instead, they’ve push the roles higher up the value chain. SREs now need to focus more on domain-specific reliability trade-offs, while platform engineers need to focus on architecting scalable, flexible systems.
💡Key Takeaways
Draw a clean boundary between Platform and SRE: Platform Engineering owns the internal product that drives developer throughput (self-service scaffolds, composable defaults, baseline telemetry); SRE owns runtime reliability (SLIs/SLOs, error budgets, incident policy). Write it down once and use it to resolve ownership questions.
Measure for the audience that cares: Platform reports SPACE/DORA-style flow metrics (lead time, deployment frequency, developer satisfaction); SRE reports reliability metrics (SLO attainment, change failure rate, MTTR). One dashboard rarely serves both.
Bake observability into the paved road: Platform standardizes logging, metrics, tracing, and ID propagation in templates; SRE layers service SLOs and alert policy on top. Shared, consistent telemetry is the substrate for faster detection and remediation.
Prefer modular, replaceable platform components: Treat each capability (provisioning, identity, CI/CD, observability) as a contract behind an adapter so tools can be swapped without large migrations; this keeps the platform evolvable as needs change.
Be explicit about build-vs-buy: Use lightweight ADRs with total cost of ownership and blast-radius analysis; build when the capability encodes org-specific guardrails or yields durable advantage, adopt when it doesn’t.
Help shape Part 2 of our SRE ↔ Platform series and The Platform Engineer’s Handbook: Take this 60-second survey
🧠Expert Insight
From Enablement to Reliability: How Platform Engineering Aligns with SRE Goals – A conversation with Sean Alvarez and Ajay Chankramath

Platform Engineering is often confused with Site Reliability Engineering (SRE) or seen as the latest rebranding of DevOps. In reality, it represents a distinct shift: treating internal platforms as products, designed for adoption and developer experience. In this conversation, we speak with
🛠️Tool of the Week
OpenFeature (CNCF Incubating): A vendor-neutral standard for feature flags with SDKs and a fast, lightweight daemon (flagd)—ideal for platform teams that want one contract across multiple providers.
Production use: Adopters include Dynatrace, eBay, Proofpoint, Redpanda, and more.
Actively updated:
flagdshipped releases in July 2025 (v0.12.x).CNCF project: Incubating status since Nov 2023.
Sponsored:
Take control, not the blame: If CIAM lives with engineering but security still takes the heat, give your team direct control over customer-app policies. Frontegg’s AI Security Suite adds: adaptive anomaly detection, identity/session protection (e.g., impossible travel), policy automation at scale, and operational visibility that fits your SecOps workflow. Start your free trial.
📎Tech Briefs
AI Helps—If You Do These 7 Things (DORA 2025): Our short read on DORA’s new report: AI use is now the norm, throughput is rising, but stability lags unless teams fix system constraints; we outline seven levers that make teams high-achievers.
GitHub Copilot code review lands in IDEs: Official docs now walk through requesting AI code reviews in Visual Studio (tabs for JetBrains/VS Code too); useful for PR prep and local change review.
OpenTelemetry Java SDK 1.54.1: Fresh patch release fixes a Prometheus protobuf regression; keep agents and collectors aligned if you export metrics to Prometheus.
Kubebuilder 4.9.0: New release upgrades controller-runtime (v0.22.1) and kustomize (v5.7.1), improves Docker builds for sparse projects, and tightens e2e tests—nice quality-of-life for operator teams.
AWS: Nova Act IDE extension: Amazon announces an IDE extension to speed up building Nova agents; another signal that agent workflows are moving into mainstream dev tooling.
That’s all for today. Thank you for reading this issue of Deep Engineering. We’re just getting started, and your feedback will help shape what comes next. Do take a moment to fill out this short survey we run monthly—as a thank-you, we’ll add one Packt credit to your account, redeemable for any book of your choice.
We’ll be back next week with more expert-led content.
Stay awesome,
Sushma Reddy (Content Engineer), Srishti Seth (Relationship Lead), and Divya Anne Selvaraj (Editor-in-Chief, Deep Engineering)
If your company is interested in reaching an audience of developers, software engineers, and tech decision makers, you may want to advertise with us.
 | A guest post by
|
 | A guest post by
|
 | A guest post by
|