



Arena-based memory management
An Excerpt from "Chapter 10: Arena-Based Memory Management and Other Optimizations" in the book C++ Memory Management by Patrice Roy (Packt, March 2025)

The idea behind arena-based memory management is to allocate a chunk of memory at a known moment in the program and manage it as a “small, personalized heap” based on a strategy that benefits from knowledge of the situation or of the problem domain.
There are many variants on this general theme, including the following:
In a game, allocate and manage the memory by scene or by level, deallocating it as a single chunk at the end of said scene or level. This can help reduce memory fragmentation in the program.
When the conditions in which allocations and deallocations are known to follow a given pattern or have bounded memory requirements, specialize allocation functions to benefit from this information.
Express a form of ownership for a group of similar objects in such as way as to destroy them all at a later point in the program instead of doing so one object at a time.
The best way to explain how arena-based allocation works is probably to write an example program that uses it and shows both what it does and what benefits this provides. We will write code in such a way as to use the same test code with either the standard library-provided allocation functions or our own specialized implementation, depending on the presence of a macro, and, of course, we will measure the allocation and deallocation code to see whether there is a benefit to our efforts.
Specific example – size-based implementation
Suppose we are working on a video game where the action converges toward a stupendous finale where Orcs and Elves meet in a grandiose battle. No one really remembers why these two groups hate each other, but there is a suspicion that one day, one of the Elves said to one of the Orcs “You know, you don’t smell all that bad today!” and this Orc was so insulted that it started a feud that still goes on today. It’s a rumor, anyway.
It so happens that, in this game, some things are known about the behavior of Orc-using code, specifically, the following:
There will never be more than a certain number of dynamically allocated
Orcobjects overall, so we have an upper bound to the space required to store these beasties.The Orcs that die will not come back to life in that game, as there are no shamans to resurrect them. Expressed otherwise, there is no need to implement a strategy that reuses the storage of an
Orcobject once it has been destroyed.
These two properties open algorithmic options for us:
If we have enough memory available, we could allocate upfront a single memory block large enough to put all the
Orcobjects in the game as we know what the worst-case scenario isSince we know that we will not need to reuse the memory associated with individual
Orcobjects, we can implement a simple (and very fast) strategy for allocation that does almost no bookkeeping and, as we will see, lets us achieve deterministic, constant-time allocation for this type
For the sake of this example, the Orc class will be represented by three data members, name (a char[4] as these beasties have a limited vocabulary), strength (of type int), and smell (of the double type as these things have… a reputation), as follows:
class Orc {
char name[4]{ 'U', 'R', 'G' };
int strength = 100;
double smell = 1000.0;
public:
static constexpr int NB_MAX = 1'000'000;
// ...
};We will use arbitrary default values for our Orc objects as we are only concerned about allocation and deallocation for this example. You can write more elaborate test code that uses non-default values if you feel like it, of course, but that would not impact our discussion so we will target simplicity.
Since we are discussing the memory allocation of a large block upfront through our size-based arena, we need to look at memory size consumption for Orc objects. Supposing sizeof(int)==4 and sizeof(double)==8 and supposing that, being fundamental types, their alignment requirements match their respective sizes, we can assume that sizeof(Orc)==16 in this case. If we aim to allocate enough space for all Orc objects at once, ensuring sizeof(Orc) remains reasonable for the resources at our disposal is important. For example, defining the maximum number of Orc objects in a program as Orc::NB_MAX and the maximal amount of memory we can allocate at once for Orc objects as some hypothetical constant named THRESHOLD, we could leave a static_assert such as the following in our source code as a form of constraints-respected check:
static_assert(Orc::NB_MAX*sizeof(Orc) <= THRESHOLD);This way, if we end up evolving the Orc class to the point where resources become an issue, the code will stop compiling and we will be able to reevaluate the situation. In our case, with a memory consumption of approximately 16 MB, we will suppose we are within budget and that we can proceed with our arena.
We will want to compare our arena-based implementation with a baseline implementation, which, in this case, will be the standard library-provided implementation of the memory allocation functions. It’s important to note upfront that each standard library implementation provides its own version of these functions, so you might want to run the code we will be writing here on more than one implementation to get a better perspective on the impact of our techniques.
To write code that allows us to do a proper comparison, we will need two distinct executables as we will be in an either/or situation (we either get the standard version or the “homemade” one we are writing), so this is a good use case for macro-based conditional compilation. We will thus write a single set of source files that will conditionally replace the standard library-provided versions of the allocation operators with ours but will otherwise be essentially identical.
We will work from three files: Orc.h, which declares the Orc class and the conditionally defined allocation operator overloads; Orc.cpp, which provides the implementation for these overloads as well as the arena implementation itself; and a test program that allocates Orc::NB_MAX objects of type Orc then later destroys them and measures the time it takes to do these two operations. Of course, as with most microbenchmarks, take these measurements with a grain of salt: the numbers will not be the same in a real program where allocations are interspersed with other code, but at least we will apply the same tests to both implementations of the allocation operators so the comparison should be reasonably fair.
Declaring the Orc class
First, let us examine Orc.h, which we have already seen in part when showing the data member layout of the Orc class earlier:
#ifndef ORC_H
#define ORC_H
// #define HOMEMADE_VERSION
#include <cstddef>
#include <new>
class Orc {
char name[4]{ 'U', 'R', 'G' };
int strength = 100;
double smell = 1000.0;
public:
static constexpr int NB_MAX = 1'000'000;
#ifdef HOMEMADE_VERSION
void * operator new(std::size_t);
void * operator new[](std::size_t);
void operator delete(void *) noexcept;
void operator delete[](void *) noexcept;
#endif
};
#endifThe HOMEMADE_VERSION macro can be uncommented to use our version of the allocation functions. As can be expected, since we are applying a special strategy for the Orc class and its expected usage patterns, we are using member-function overloads for the allocation operators. (We would not want to treat int objects or – imagine! – Elves the same way we will treat Orcs, would we? I thought not.)
Defining the Orc class and implementing an arena
The essence of the memory management-related code will be in Orc.cpp. We will go through it in two steps, the arena implementation and the allocation operator overloads, and analyze the different important parts separately. The whole implementation found in this file will be conditionally compiled based on the HOMEMADE_VERSION macro.
We will name our arena class Tribe, and it will be a singleton. Yes, that reviled design pattern we used in Chapter 8 again, but we really do want a single Tribe object in our program so that conveys the intent well. The important parts of our implementation are as follows:
The default (and only) constructor of the
Tribeclass allocates a single block ofOrc::NB_MAX*sizeof(Orc)bytes. It is important to note right away that there are noOrcobjects in that chunk: this memory block is just the right size and shape to put all theOrcobjects we will need. A key idea for arena-based allocation is that, at least for this implementation, the arena manages raw memory, not objects: object construction and destruction are the province of user code, and any object not properly destroyed at the end of the program is user code’s fault, not the fault of the arena.We validate at once that the allocation succeeded. I used an
assert()in this case, as the rest of the code depends on this success, but throwingstd::bad_allocor callingstd::abort()would also have been reasonable options. ATribeobject keeps two pointers,pandcur, both initially pointing at the beginning of the block. We will usepas the beginning of block marker, andcuras the pointer to the next block to return; as such,pwill remain stable throughout program execution andcurwill move forward bysizeof(Orc)bytes with each allocation.
Using char* or Orc*
This Tribe implementation uses char* for the p and cur pointers but Orc* would have been a correct choice also. One simply needs to remember that, as far as the Tribe object is concerned, there are no Orc objects in the arena and the use of type Orc* is simply a convenient lie to simplify pointer arithmetic. The changes this would entail would be replacing static_cast<char*> with static_cast<Orc*> in the constructor, and replacing cur+=sizeof(Orc) with ++cur in the implementation of the allocate() member function. It’s mostly a matter of style and personal preference.
The destructor frees the entire block of memory managed by the
Tribeobject. This is a very efficient procedure: it’s quicker than separately freeing smaller blocks, and it leads to very little memory fragmentation.This first implementation uses the Meyers singleton technique seen in Chapter 8, but we will use a different approach later in this chapter to compare the performance impacts of two implementation strategies for the same design pattern… because there are such impacts, as we will see.
The way our size-based arena implementation will benefit from our a priori knowledge of the expected usage pattern is as follows:
Each allocation will return a sequentially “allocated”
Orc-sized block, meaning that there is no need to search for an appropriately sized block – we always know where it is.There is no work to do when deallocating as we are not reusing the blocks once they have been used. Note that, per standard rules, the allocation and deallocation functions have to be thread-safe, which explains our use of
std::mutexin this implementation.
The code follows:
#include "Orc.h"
#ifdef HOMEMADE_VERSION
#include <cassert>
#include <cstdlib>
#include <mutex>
class Tribe {
std::mutex m;
char *p, *cur;
Tribe() : p{ static_cast<char*>(
std::malloc(Orc::NB_MAX * sizeof(Orc))
) } {
assert(p);
cur = p;
}
Tribe(const Tribe&) = delete;
Tribe& operator=(const Tribe&) = delete;
public:
~Tribe() {
std::free(p);
}
static auto &get() {
static Tribe singleton;
return singleton;
}
void * allocate() {
std::lock_guard _ { m };
auto q = cur;
cur += sizeof(Orc);
return q;
}
void deallocate(void *) noexcept {
}
};
// ...As you might have guessed already, these allocation conditions are close to optimal, but they happen more often than we would think in practice. A similarly efficient usage pattern would model a stack (the last block allocated is the next block freed), and we write code that uses local variables every day without necessarily realizing that we are using what is often an optimal usage pattern for the underlying memory.
We then come to the overloaded allocation operators. To keep this implementation simple, we will suppose there will be no array of Orc objects to allocate, but you can refine the implementation to take arrays into account (it’s not a difficult task; it’s just more complicated to write relevant test code). The role played by these functions is to delegate the work to the underlying arena, and they will only be used for the Orc class (there is a caveat to this, which will be discussed in the When parameters change section later in this chapter). As such, they are almost trivial:
// ...
void * Orc::operator new(std::size_t) {
return Tribe::get().allocate();
}
void * Orc::operator new[](std::size_t) {
assert(false);
}
void Orc::operator delete(void *p) noexcept {
Tribe::get().deallocate(p);
}
void Orc::operator delete[](void *) noexcept {
assert(false);
}
#endif // HOMEMADE_VERSIONTesting our implementation
We then come to the test code implementation we will be using. This program will be made of a microbenchmark function named test() and of a main() function. We will examine both separately.
The test() function will take a non-void function, f(), a variadic pack of arguments, args, and call f(args...) making sure to use perfect forwarding for the arguments in that call to make sure the arguments are passed with the semantic intended in the original call. It reads a clock before and after the call to f() and returns a pair made of the result of executing f(args...) and the time elapsed during this call. I used high_resolution_clock in my code but there are valid reasons to use either system_clock or steady_clock in this situation:
#include <chrono>
#include <utility>
template <class F, class ... Args>
auto test(F f, Args &&... args) {
using namespace std;
using namespace std::chrono;
auto pre = high_resolution_clock::now();
auto res = f(std::forward<Args>(args)...);
auto post = high_resolution_clock::now();
return pair{ res, post - pre };
}
// ...You might wonder why we are requiring non-void functions and returning the result of calling f(args...) even if, in some cases, the return value might be a little artificial. The idea here is to ensure that the compiler thinks the result of f(args...) is useful and does not optimize it away. Compilers are clever beasts indeed and can remove code that seems useless under what is colloquially known as the “as-if rule” (simply put, if there is no visible effect to calling a function, just get rid of it!).
For the test program itself, pay attention to the following aspects:
First, we will use
std::vector<Orc*>, notstd::vector<Orc>. This might seem strange at first, but since we are testing the speed ofOrc::operator new()andOrc::operator delete(), we will want to actually call these operators! If we were using a container ofOrcobjects, there would be no call to our operators whatsoever.We call
reserve()on thatstd::vectorobject before running our tests, to allocate the space to put the pointers to theOrcobjects we will be constructing. That is an important aspect of our measurements: calls topush_back()and similar insertion functions in astd::vectorobject will need to reallocate if we try to add an element to a full container, and this reallocation will add noise to our benchmarks, so ensuring the container will not need to reallocate during the tests helps us focus on what we want to measure.What we measure with our
test()function (used many times already in this book) is a sequence ofOrc::NB_MAXcalls toOrc::operator new(), eventually followed by the same number of calls toOrc::operator delete(). We suppose a carnage of sorts in the time between the constructions and the destructions, but we are not showing this violence out of respect for you, dear reader.Once we reach the end, we print out the results of our measurements, using microseconds as the measurement unit – our computers today are fast enough that milliseconds would probably not be granular enough.
The code follows:
// ...
#include "Orc.h"
#include <print>
#include <vector>
int main() {
using namespace std;
using namespace std::chrono;
#ifdef HOMEMADE_VERSION
print("HOMEMADE VERSION\n");
#else
print("STANDARD LIBRARY VERSION\n");
#endif
vector<Orc*> orcs;
auto [r0, dt0] = test([&orcs] {
for(int i = 0; i != Orc::NB_MAX; ++i)
orcs.push_back(new Orc);
return size(orcs);
});
// ...
// CARNAGE (CENSORED)
// ...
auto [r1, dt1] = test([&orcs] {
for(auto p : orcs)
delete p;
return size(orcs);
});
print("Construction: {} orcs in {}\n",
size(orcs), duration_cast<microseconds>(dt0));
print("Destruction: {} orcs in {}\n",
size(orcs), duration_cast<microseconds>(dt1));
}At this point, you might wonder whether this is all worth the effort. After all, our standard libraries are probably very efficient (and indeed, they are, on average, excellent!). The only way to know whether the results will make us happy is to run the test code and see for ourselves.
Looking at the numbers
Using an online gcc 15 compiler with the -O2 optimization level and running this code twice (once with the standard library version and once with the homemade version using a Meyers singleton), I get the following numbers for calls to the new and delete operators on Orc::NB_MAX (here, 106) objects:
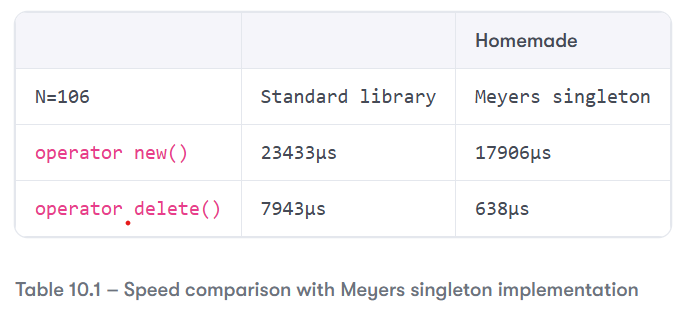
Actual numbers will vary depending on a variety of factors, of course, but the interesting aspect of the comparison is the ratio: our homemade operator new() only took 76.4% of the time consumed by the standard library-provided version and our homemade operator delete() took… 8.03% of the time required by our baseline.
Those are quite pleasant results, but they should not really surprise us: we perform constant-time allocation and essentially “no time” deallocation. We do take the time to lock and unlock a std::mutex object on every allocation, but most standard libraries implement mutexes that expect low contention and are very fast under those circumstances, and it so happens that our program does single-threaded allocations and deallocations that lead to code that is clearly devoid of contention.
Now, your acute reasoning skills might lead you to be surprised that deallocation is not actually faster than what we just measured. It’s an empty function we are calling, after all, so what’s consuming this CPU time?
The answer is… our singleton, or more precisely, access to the static local variable used for the Meyers implementation. Remember from Chapter 8 that this technique aims to ensure that a singleton is created when needed, and static local variables are constructed the first time their enclosing function is called.
C++ implements “magic statics” where the call to the static local object’s constructor is guarded by synchronization mechanisms that ensure the object is constructed only once. As we can see, this synchronization, efficient as it is, is not free. In our case, if we can guarantee that no other global object will need to call Tribe::get() before main() is called, we can replace the Meyers approach with a more classical approach where the singleton is simply a static data member of the Tribe class, declared within the scope of that class and defined at global scope:
// ...
// "global" singleton implementation (the rest of
// the code remains unchanged)
class Tribe {
std::mutex m;
char *p, *cur;
Tribe() : p{ static_cast<char*>(
std::malloc(Orc::NB_MAX * sizeof(Orc))
) } {
assert(p);
cur = p;
}
Tribe(const Tribe&) = delete;
Tribe& operator=(const Tribe&) = delete;
static Tribe singleton;
public:
~Tribe() {
std::free(p);
}
static auto &get() {
return singleton;
}
void * allocate() {
std::lock_guard _ { m };
auto q = cur;
cur += sizeof(Orc);
return q;
}
void deallocate(void *) noexcept {
}
};
// in a .cpp file somewhere, within a block surrounded
// with #ifdef HOMEMADE_VERSION and #endif
Tribe Tribe::singleton;
// ...Moving the definition of the singleton object away from within the function – placing it at global scope – removes the need for synchronization around the call to its constructor. We can now compare this implementation with our previous results to evaluate the costs involved, and the gains to be made (if any).
With the same test setup as used previously, adding the “global” singleton to the set of implementations under comparison, we get the following:
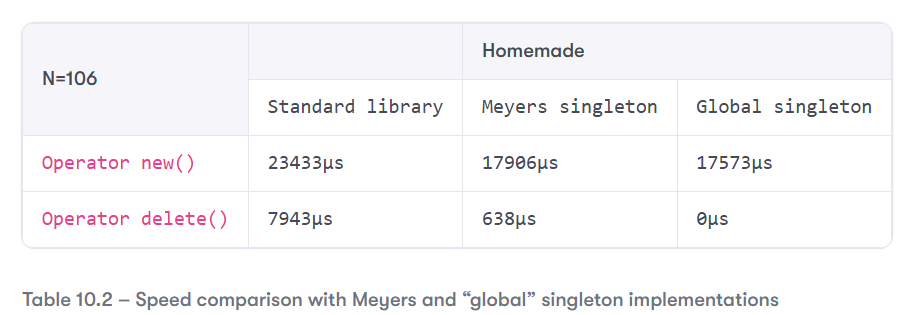
Now, this is more like it! The calls to operator new() are slightly faster than they were 74.99% (of the time it took with the standard library version, and 98.14% of the time it took with the Meyers singleton), but the calls to operator delete() have become no-ops. It’s hard to do better than this!
So, is it worth the effort? It depends on your needs, of course. Speed is a factor; in some programs, the speed gain can be a necessity, but in others, it can be a non-factor or almost so. The reduction in memory fragmentation can make a big difference in some programs too, and some will use arenas precisely for that reason. The point is this: if you need to do this, now you know how.
Generalizing to SizeBasedArena<T,N>
The Tribe class as written seems specific to the Orc class but, in practice, it really is specific to Orc-sized objects as it never calls any function of the Orc class; it never constructs an Orc object, nor does it ever destroy one. This means that we could turn that class into a generic class and reuse it for other types that are expected to be used under similar constraints.
To achieve this, we would decouple the arena code from the Orc class and put it in a separate file, maybe called SizeBasedArena.h, for example:
#ifndef SIZE_BASED_ARENA_H
#define SIZE_BASED_ARENA_H
#include <cassert>
#include <cstdlib>
#include <mutex>
template <class T, std::size_t N>
class SizeBasedArena {
std::mutex m;
char *p, *cur;
SizeBasedArena() : p{ static_cast<char*>(
std::malloc(N * sizeof(T))
) } {
assert(p);
cur = p;
}
SizeBasedArena(const SizeBasedArena&) = delete;
SizeBasedArena&
operator=(const SizeBasedArena&) = delete;
public:
~SizeBasedArena() {
std::free(p);
}
static auto &get() {
static SizeBasedArena singleton;
return singleton;
}
void * allocate_one() {
std::lock_guard _ { m };
auto q = cur;
cur += sizeof(T);
return q;
}
void * allocate_n(std::size_t n) {
std::lock_guard _ { m };
auto q = cur;
cur += n * sizeof(T);
return q;
}
void deallocate_one(void *) noexcept {
}
void deallocate_n(void *) noexcept {
}
};
#endifIt might be surprising that we used T and N as template parameters. Why type T instead of an integer initialized with sizeof(T) if we do not use T in the arena? Well, if the Elf class (for example) used a size-based arena too, and if we were unlucky enough that sizeof(Orc)==sizeof(Elf), then basing ourselves on the sizes of the types rather than on the types themselves might, if the values for their respective N parameters are the same, lead Orc and Elf to use the same arena… and we do not want that (nor do they!).
To simplify the initialization of the singleton in this generic example, we went back to the Meyers technique. It’s more difficult to guarantee the absence of interdependence at construction time for global objects when writing generic code than it was writing the Orc-specific equivalent, as the move to generic code just enlarged the potential user base significantly.
The implementation in Orc.cpp would now be as follows:
#include "Orc.h"
#ifdef HOMEMADE_VERSION
#include "SizeBasedArena.h"
using Tribe = SizeBasedArena<Orc, Orc::NB_MAX>;
void * Orc::operator new(std::size_t) {
return Tribe::get().allocate_one();
}
void * Orc::operator new[](std::size_t n) {
return Tribe::get().allocate_n(n / sizeof(Orc));
}
void Orc::operator delete(void *p) noexcept {
Tribe::get().deallocate_one(p);
}
void Orc::operator delete[](void *p) noexcept {
Tribe::get().deallocate_n(p);
}
#endifYou might have noted that since SizeBasedArena<T,N> implements allocation functions for a single object or an array of n objects, we have extended the Orc class’s member function allocation operator overloads to cover operator new[]() and operator delete[](). There’s really no reason not to do so at this point.
To learn about what happens when parameters change and to access more practical examples, performance tips, and real-world patterns—check out Patrice Roy’s book, C++ Memory Management, available from Packt:

Here is what some readers have said:


 | A guest post by
|